Taiqi Lang 学习笔记 基础篇
Taiqi简介
Taichi是一种专为高性能并行计算而设计的特定领域语言,内嵌于Python中。
在编写计算密集型任务时,用户只需遵循一组额外的规则,并使用@ti.func和@ti.kernel这两个装饰器,就能充分利用Taichi的高性能计算功能。
这些装饰器指示 Taichi 接管计算任务,并使用其即时(JIT)编译器将装饰函数编译为机器代码。因此,对这些函数的调用可在多核CPU或GPU上执行,与本地Python代码相比,可实现 50~100 倍的加速。
语言特性
- 高性能并行计算
- 自动微分
- 灵活数据布局
- 空间稀疏数据结构
安装
Taichi 是一个 PyPI 包
1 | |
初始化
1 | |
参数
arch指定将执行编译代码的后端。此后端可以是ti.cpu或ti.gpu。如果指定了该ti.gpu选项,Taichi 将尝试按以下顺序使用 GPU 后端:ti.cuda、ti.vulkan和ti.opengl/ti.Metal。如果没有可用的 GPU 架构,CPU 将用作后端。也可以直接指定后端,若不可以则报错
Taichi 内核 与 Taichi 函数
Taichi 和 Python 的语法相似,但它们并不完全相同。为了区分 Taichi 代码和原生 Python 代码,我们使用了两个装饰器,@ti.kernel以及@ti.func
只有被@ti.kernel以及@ti.func修饰的才属 Taichi 的作用域,其他均为 Python 作用域
- Taichi 内核
@ti.kernel是 Taichi 运行时接管任务的入口点,它们必须由 Python 代码直接调用,不允许从另一个内核内部或从 Taichi 函数内部调用内核 - Taichi 函数
@ti.func是内核的构建块,只能由另一个 Taichi 函数或内核调用
从原生 Python 代码(Python 作用域)中调用 Taichi 函数会导致 Taichi 引发语法错误
1 | |
可以在单个 Taichi 程序中定义多个内核。这些内核彼此独立,并按照首次调用的顺序进行编译和执行。编译后的内核会被缓存,以减少后续调用的启动开销
参数
无论是Taiqi内核还是Taiqi函数,传参的策略都是Pass by value
一个内核可以接受多个参数。但是不能将任意 Python 对象传递给内核。这是因为 Python 对象可以是动态的,并且可能包含 Taichi 编译器无法识别的数据
内核可以接受各种参数类型,包括标量、ti.types.matrix() 、ti.types.vector() 、ti.types.struct()、ti.types.ndarray() 和 ti.template().这些参数类型可以轻松地将数据从 Python 作用域传递到 Taichi 作用域。可以在ti.types模块中找到支持的类型
Taiqi内核和Taiqi函数在编译的时候会捕获Python作用域中的全局变量,并将其绑定作为常量传递至Taiqi作用域,而不会感知其值的变化
Taiqi 内核限制
- 参数需要类型提示
1 | |
- 若有返回语句,返回值要有类型提示
- 最多一个
return返回语句,最多一个返回值 - 除了 CPU 和 CUDA 后端,返回值不能为结构图类型
ti.types.struct()
1 | |
Taiqi 函数限制
可以在一个函数内套用其他函数,但不能递归(强制内联)
两者对比总结
| Taiqi 内核 | Taiqi 函数 | |
|---|---|---|
| 调用范围 | Python 作用域 | Taiqi 作用域 |
| 参数的类型提示 | 必需 | 推荐 |
| 返回值的类型提示 | 必需 | 推荐 |
| 参数的元素上限 | 64(OpenGL后端为32) | 无限制 |
return语句上限 |
1 | 无限制 |
| 返回值数量上限 | 1 | 无限制 |
Taiqi 内核中的并行 For 循环
在 Taiqi 内核中的作用域中,最外层中的 For 循环会自动并行化执行,此时无法使用break等语句
在 Taiqi 中+=相当于原子操作ti.atomic_add(),来避免在并行执行 中出现数据征用的问题
数据类型
Taichi 是一种静态类型编程语言,这意味着 Taichi 范围内变量的类型是在编译时确定的。这意味着一旦声明变量,就不能为其分配不同类型的值
与Python不同的是,要注意静态变量的词法作用域
1 | |
Taichi 中的ti.types模块定义了所有支持的数据类型。这些数据类型分为两组:原始数据类型和复合数据类型
原始数据类型
Taichi 中的原始数据类型是标量,它们是构成复合数据类型的最小单位。这些类型用指示其类别的字母表示,后跟指示其位精度的数字。有符号整数是i,无符号整数是u,浮点数是f。精度位可以是8、16、32 或 64
不同后端对 Taichi 原始类型的支持可能有所不同。有关详细信息,参阅下表
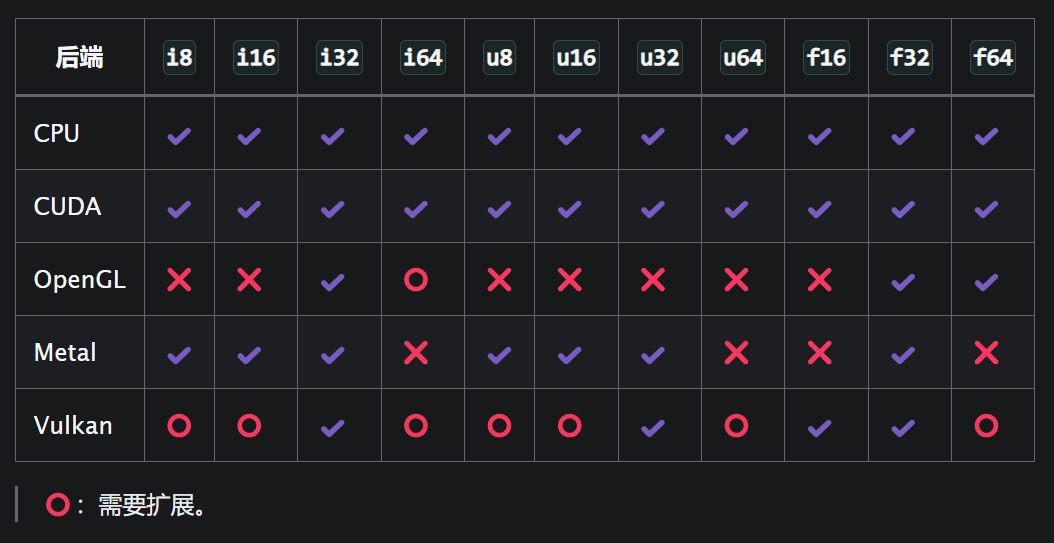
Taichi 作用域中的数字文字具有默认的整数或浮点类型,允许你在调用init()时指定默认的基本数据类型,并在 Taichi 作用域和 Taichi 数据容器中使用两个名称int和float分别用作默认整数和浮点类型的别名
1 | |
为了保证工程模拟等应用的高精度,建议将
default_fp设置ti.f64
例如,如果默认浮点类型为ti.f32,则数字文字 3.14159265358979 将转换为精度约为 7 位十进制数字的 32 位浮点数
显式类型转换
Taiqi 中一旦声明变量,就无法改变其数据类型。 因此,当原始数据类型无法用于赋值或计算时,可以先将值切换到不同的数据类型,再进行复制与计算。(并非切换变量的数据类型)
使用ti.cast()函数将给定值转换为特定的目标类型
1 | |
例如
1 | |
也可使用ti.f32和ti.i64等基本类型,直接对标量变量执行类型转换
1 | |
隐式类型转化
一般来说,隐式类型转换可能是错误的重要来源。因此,Taichi 强烈反对使用此机制,并建议您为所有变量和操作显式指定所需的数据类型
二元运算中的隐式类型转换规则(优先级由高到低):
- 整数 + 浮点 -> 浮点数
- 低精度位 + 高精度位 -> 高精度位
- 带符号整数 + 无符号整数 -> 无符号整数
出现规则冲突时,最高优先级的规则适用
例外:
- 位移运算返回 lhs (左侧) 数据类型
- 逻辑运算返回
i32 - 比较运算返回
i32
赋值时的隐式类型转换
当为具有不同数据类型的变量赋值时,会执行隐式类型转换,如果该值的精度高于目标变量,则会显示一条警告,指示潜在的精度损失
1 | |
复合类型
复合类型是用户自定义的数据类型,由多个元素组成。 支持的复合类型包括向量、矩阵、ndarray 和结构体。Taichi 允许你将ti.types模块中提供的所有类型作为脚手架来自定义更高等级的复合类型
矩阵和向量
使用两个函数ti.types.matrix()和ti.types.vector()来创建自己的矩阵和向量类型
1 | |
利用自定义复合类型来实例化向量和矩阵,以及注释函数参数和结构成员的数据类型
1 | |
对于四维以下的向量,可以使用xyzw或rgba来访问向量的内容
1 | |
结构体类型和数据类(dataclass)
使用函数ti.types.struct()创建结构类型
1 | |
当定义一个具有大量参数的结构体时,使用ti.types.struct可能会导致代码杂乱无章。 可通过@ti.dataclass装饰器,使代码更优雅
1 | |
另外使用@ti.dataclass的还可以在数据类中定义成员函数,从而实现面向对象编程(OOP) 功能
实例化
在对复合类型实例化时,未赋值的参数自动被设为0
在自定义向量和矩阵类型中,用单标量初始化时,会自动将其扩展到所有的元素
但使用预设ti.Vector()和ti.Matrix()时需传入类似数列的对象
1 | |
类型转换
目前支持类型转换的复合数据类型只有向量和矩阵。 在对向量或矩阵进行类型转换时,是以元素为单位进行的,结果是创建新的向量和矩阵
1 | |
数据容器 Field
Taichi field 是全局数据容器,从Python作用域或Taichi作用域均能访问,其元素可以是标量、向量、矩阵和结构体
Taichi field 支持的维度最高是8D
声明
- 标量field
1 | |
- 向量field
1 | |
- 矩阵field
1 | |
出于性能考虑,建议您将矩阵保持在最小水平
不推荐: ti.Matrix.field(64, 32, dtype=ti.f32, shape=(3, 2))
推荐: ti.Matrix.field(3, 2, dtype=ti.f32, shape=(64, 32))
- 结构体field
1 | |
操作
使用索引运算符[] 来访问 field 中的一个元素
1 | |
当访问一个零维 field 中的元素时,将 [None] 作为索引,而非[0]
1 | |
Taiqi field 不支持切片,会抛出错误Slicing is not supported on ti.field
1 | |
- 使用
ti.grouped()将多维场索引打包成向量(一般与for循环连用)
1 | |
- 使用
field.fill()填充标量field的元素
1 | |
- 访问向量field的元素
1 | |
- 访问矩阵field的元素
1 | |
- 访问结构体field的元素
1 | |
- 访问field的元数据
1 | |