Text-to-Video Retrieval
CNN 卷积神经网络
图解参考:
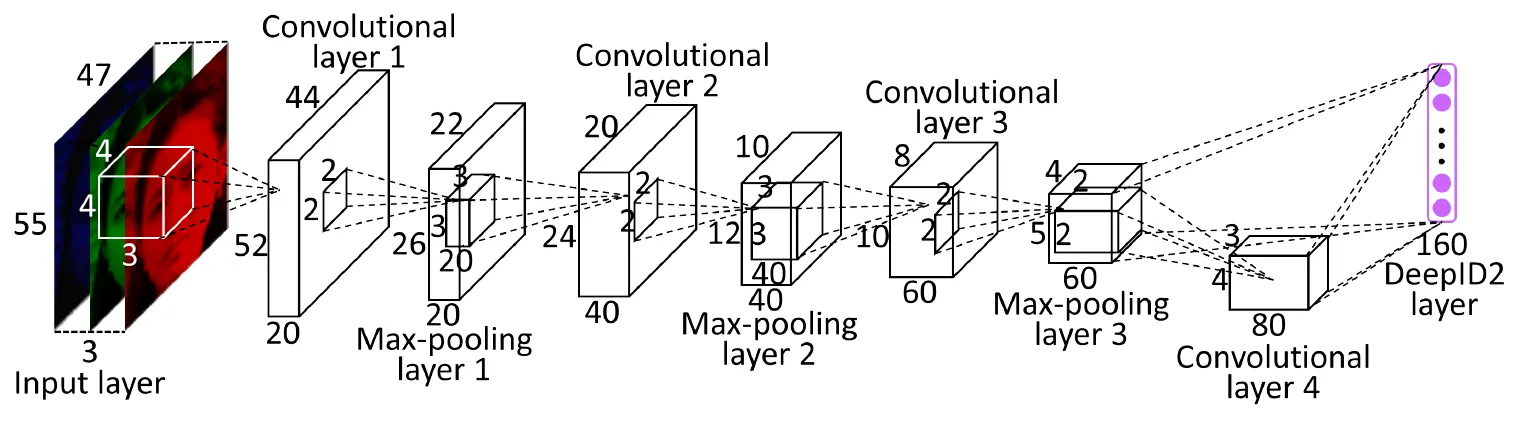
一个典型的 CNN (如RestNet)架构通常由以下几种层组合而成:
- 输入层 (Input Layer)
- 卷积层 (Convolutional Layer)
- 激活层 (Activation Layer)
- 池化层 (Pooling Layer)
- 全连接层 (Fully Connected Layer)
- 输出层 (Output Layer)
1. 输入层 (Input Layer)
- 作用: 这是整个网络的起点,负责接收最原始的数据
- 功能: 将原始图像(或其它类型数据)转换成网络可以处理的数字张量(Tensor)。对于图像而言,这个张量通常有三个维度:[高度, 宽度, 通道数]
- 高度 (Height): 图像的像素高度
- 宽度 (Width): 图像的像素宽度
- 通道数 (Channels):
- 对于灰度图,通道数为 1
- 对于常见的彩色图(RGB),通道数为 3
2. 卷积层 (Convolutional Layer) - 核心
卷积层是 CNN 的核心和灵魂,负责 特征提取
-
作用: 通过一个称为“卷积核”(Kernel 或 Filter)的小窗口在输入数据上滑动,来识别并提取图像中的局部特征,例如边缘、角点、纹理、颜色块等
-
核心组件:
- 卷积核 (Kernel/Filter): 一个小型的、包含了权重参数的矩阵(例如 3x3 或 5x5)。可以把它想象成一个“模式识别器”。不同的卷积核用来检测不同的特征。例如,一个卷积核可能对垂直边缘敏感,另一个则对水平边缘敏感。网络在训练过程中会自动学习这些权重
- 特征图 (Feature Map/Activation Map): 卷积核在整个输入图像上进行卷积运算后,得到的结果就是一个特征图。它表示了输入图像在特定特征上的激活程度。一张图上的哪些位置包含了这个卷积核想要寻找的模式,在特征图上对应位置的数值就越大
-
工作原理:
- 卷积核在输入图像上从左到右、从上到下滑动
- 在每个位置,计算卷积核与输入图像对应区域的 逐元素乘积之和(点积运算)
- 将所有计算结果组合起来,形成一张新的二维矩阵,即特征图
-
多通道处理机制:
- 输入通道匹配: 如果输入数据包含多个通道(例如 RGB 图像有 3 个通道),那么每一个卷积核的深度必须与输入的通道数保持一致(例如 3x3x3),就像一个长方体。
- 融合计算: 卷积核的每个通道分别与输入对应的通道进行卷积运算,然后将所有通道的计算结果相加(通常再加一个偏置项 Bias),最终“压扁”汇聚成一张二维的特征图。这意味着,无论输入有多少个通道,单个卷积核通过一次操作只能产生一个通道的输出。
-
通道数的扩展 (Channel Expansion):
- 多核并行: 为了捕捉图像中丰富的特征(如横向边缘、纵向边缘、色彩纹理等),一个卷积层通常包含多个卷积核(Filter/Kernel)。
- 堆叠输出: 假设我们使用了 N 个卷积核,每个卷积核都会生成一张独立的特征图。我们将这 N 张特征图在深度方向上堆叠在一起,就构成了该层的最终输出,此时,输出张量的通道数就等于该层卷积核的数量 N 。这就是为什么在 CNN 网络结构中,往往越往深层走,特征图的空间尺寸(宽/高)变小,但通道数(深度)却在不断增加。
3. 激活层 (Activation Layer)
- 作用: 引入非线性因素。这是至关重要的一步
- 功能: 如果没有激活函数,无论 CNN 有多少层,其本质上都只是一个复杂的线性变换,无法学习和合复杂的数据模式。激活函数对卷积层输出的特征图进行非线性映射,使得网络能够学习更加复杂的特征
- 常用函数:
- ReLU (Rectified Linear Unit): 这是目前最常用、最主流的激活函数。其公式为 f(x)=max(0,x)。
- 优点: 计算非常快,并且在正数区间不会出现梯度饱和(有助于缓解梯度消失问题),使得深度网络训练更容易
- 工作方式: 将特征图中的所有负数值都置为 0,保留正数值
- ReLU (Rectified Linear Unit): 这是目前最常用、最主流的激活函数。其公式为 f(x)=max(0,x)。
4. 池化层 (Pooling Layer)
- 作用: 降采样 (Downsampling) 和 特征降维。
- 功能: 对输入的特征图进行压缩,减小其空间尺寸(高度和宽度),同时保留最重要的特征信息。这样做有几个好处:
- 减少计算量: 降低后续层的参数数量和计算复杂度
- 防止过拟合: 通过减少特征维度来简化模型
- 提供平移不变性 (Translation Invariance): 即使特征在图像中的位置发生微小移动,池化操作后得到的结果也倾向于保持不变
- 常见类型:
- 最大池化 (Max Pooling): 在一个窗口内(如 2x2),选取数值最大的像素作为输出。它能最好地保留纹理等最显著的特征。这是最常用的一种
- 平均池化 (Average Pooling): 计算窗口内所有像素的平均值作为输出。它能更好地保留背景信息
注意: 池化层没有需要学习的参数。它只是一个固定的下采样操作
5. 全连接层 (Fully Connected Layer, FC Layer)
- 作用: 在经过多次卷积、激活和池化操作后,将学习到的高级特征进行 整合和分类
- 功能:
- 扁平化 (Flatten): 首先,将前一层输出的多维特征图“压平”成一个一维的向量
- 连接: 该层的每个神经元都与前一层的所有神经元相连接(这也是“全连接”名称的由来)
- 映射: 通过权重矩阵的计算,将提取到的分布式特征表示映射到样本的标签空间,最终用于分类或回归
6. 输出层 (Output Layer)
- 作用: 输出最终的预测结果
- 功能: 它通常是一个全连接层,其神经元的数量取决于任务类型
- 对于多分类任务: 神经元数量等于类别总数。通常使用 Softmax 激活函数,将输出值转换为表示每个类别概率的分布(所有概率值相加为 1)
- 对于二分类任务: 可以使用一个神经元,并配合 Sigmoid 激活函数,输出一个 0 到 1 之间的概率值
- 对于回归任务: 使用一个或多个神经元,并且不使用激活函数(或使用线性激活函数),直接输出预测的数值
RNN 循环神经网络
图解参考:
- https://www.bilibili.com/video/BV1z5411f7Bm?spm_id_from=333.788.videopod.sections&vd_source=d95f1f1b6e857449fcf25e43320f37da
- https://zhuanlan.zhihu.com/p/1926356955993215273
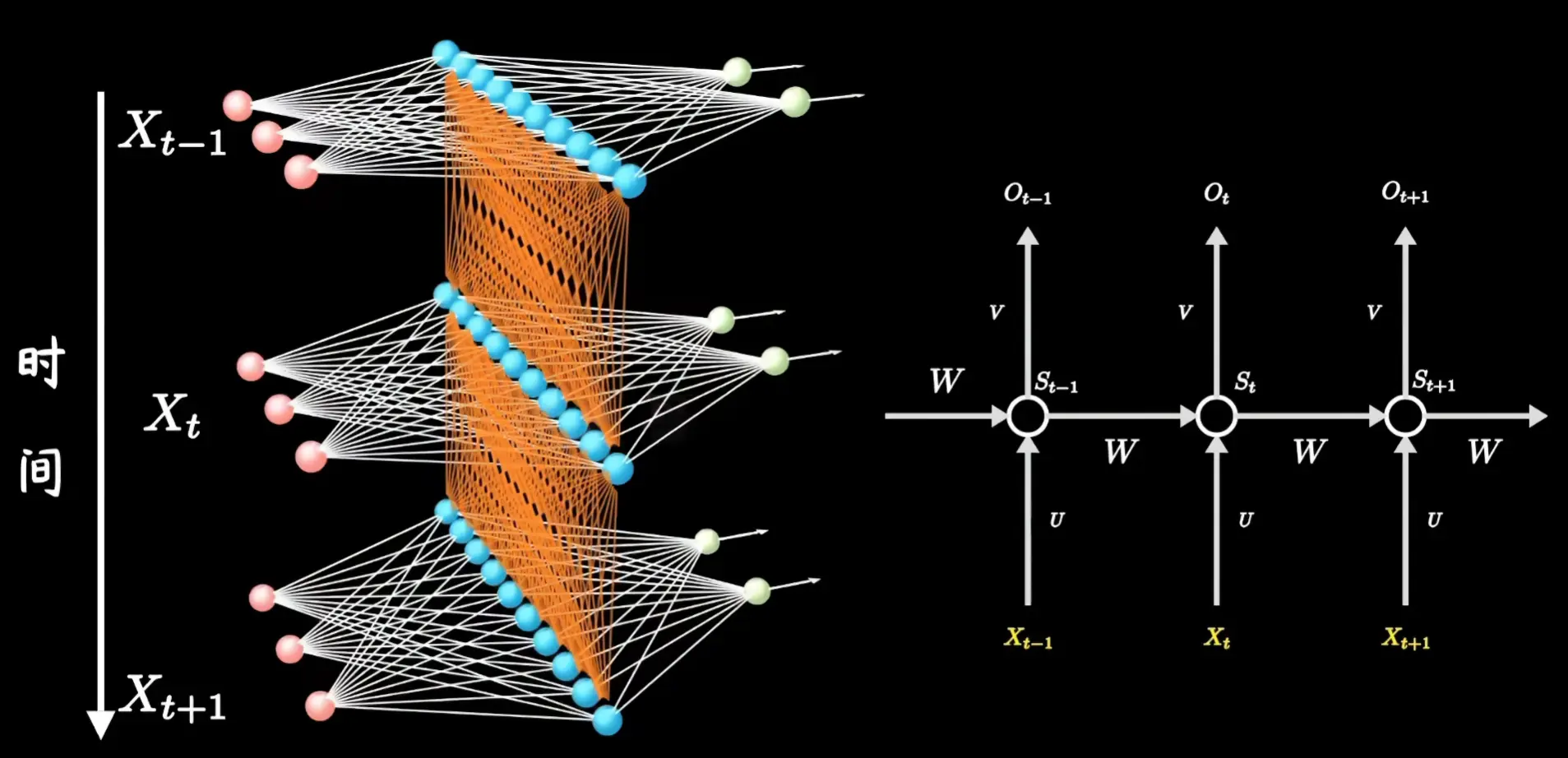
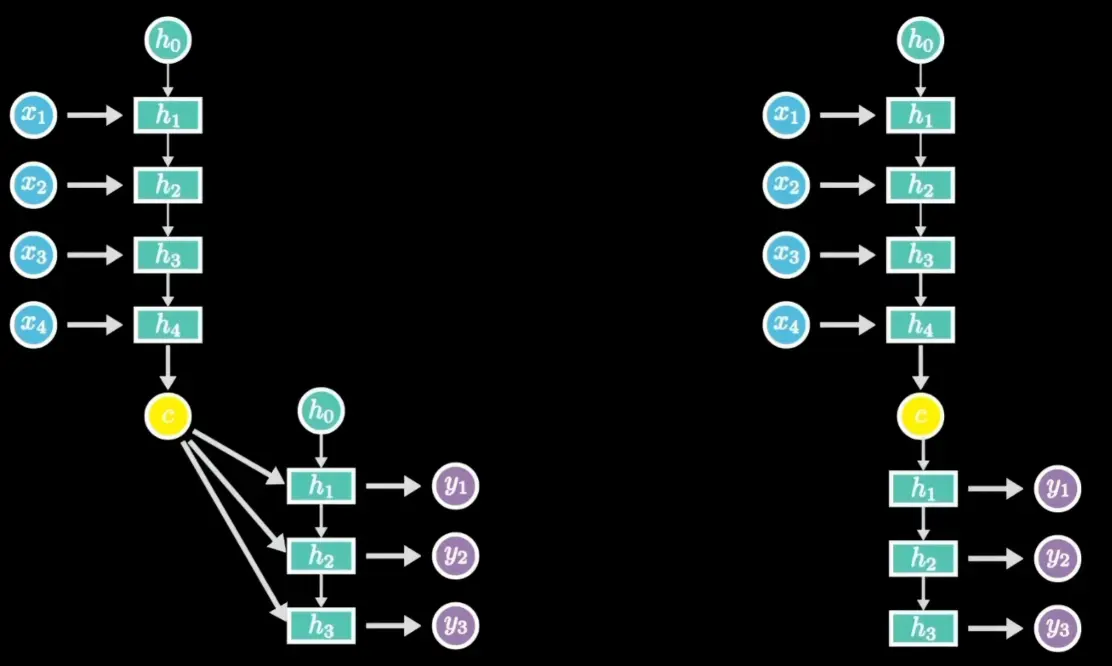
Encoder-Decoder / Seq2Seq:N->M
RNN擅长处理1->N, N->N, N->1的情况,但不擅长处理 N->M 的情况(可能需要用多个RNN堆叠),这种Encoder-Decoder架构会把其压缩成一个固定长度的中间向量,即上下文向量(Context Vector),出现**信息瓶颈(Information Bottleneck)**的问题导致信息丢失
Attention 注意力机制
图解参考:
- https://www.bilibili.com/video/BV1xS4y1k7tn/?spm_id_from=333.788.videopod.sections&vd_source=d95f1f1b6e857449fcf25e43320f37da
- https://www.bilibili.com/video/BV1G64y1S7bc/?spm_id_from=333.1387.upload.video_card.click&vd_source=d95f1f1b6e857449fcf25e43320f37da
- https://blog.csdn.net/qq_42363032/article/details/124651978
Attention机制的提出,就是为了解决上文中的信息瓶颈问题
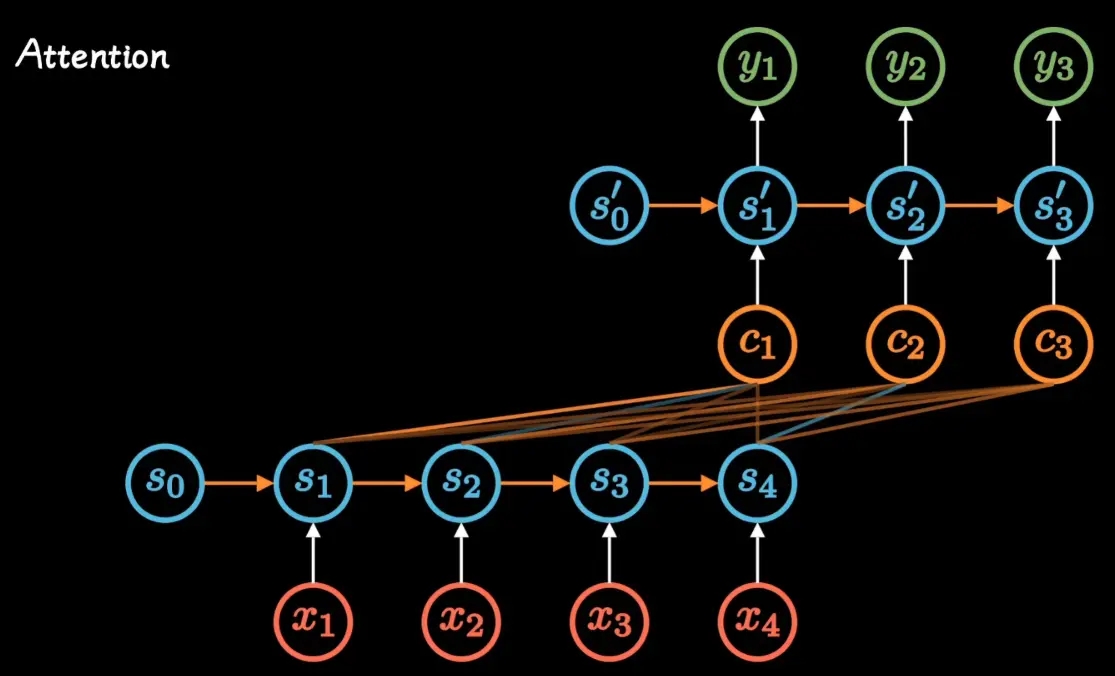
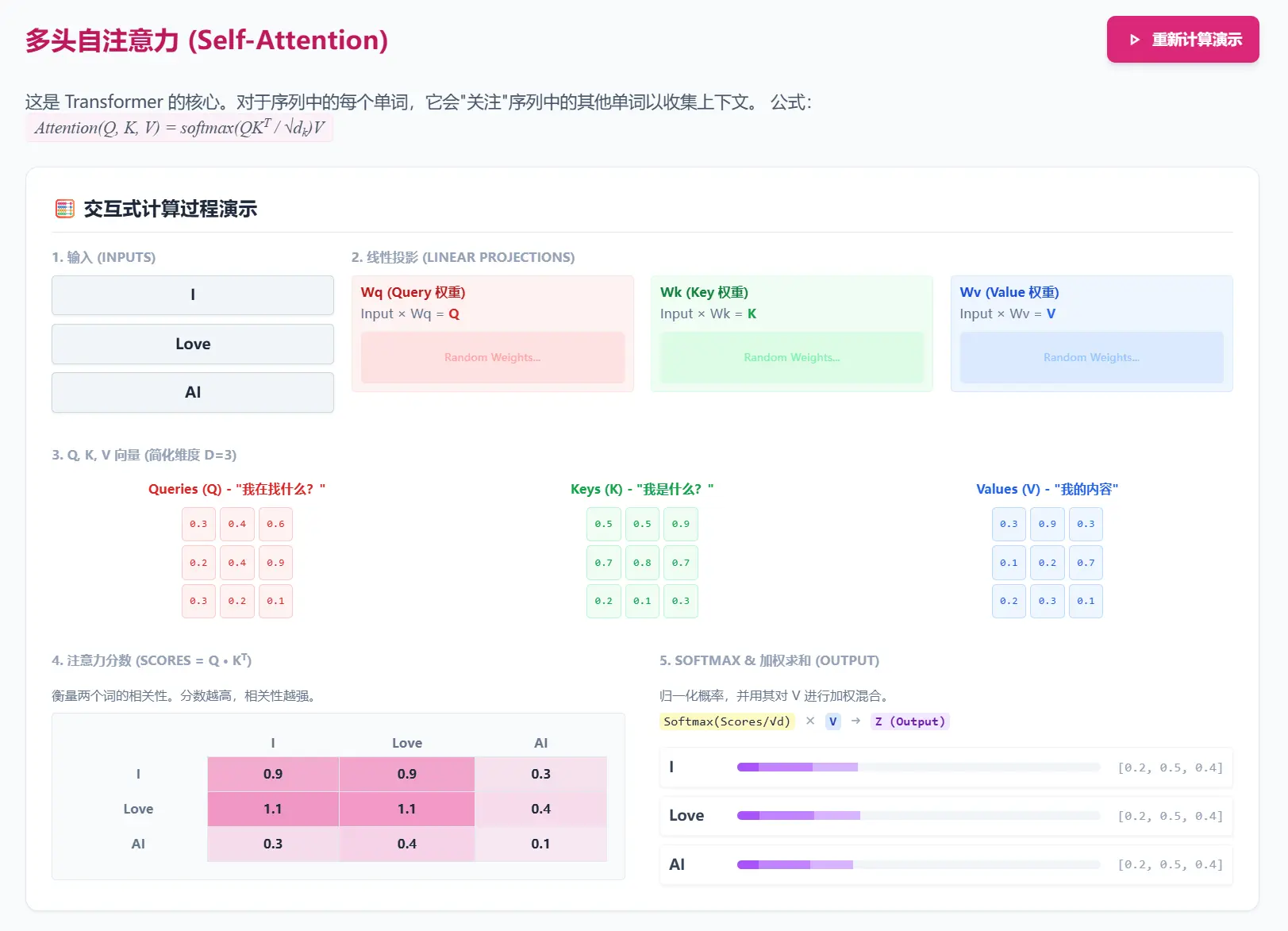
Query (Q), Key (K), 和 Value (V)
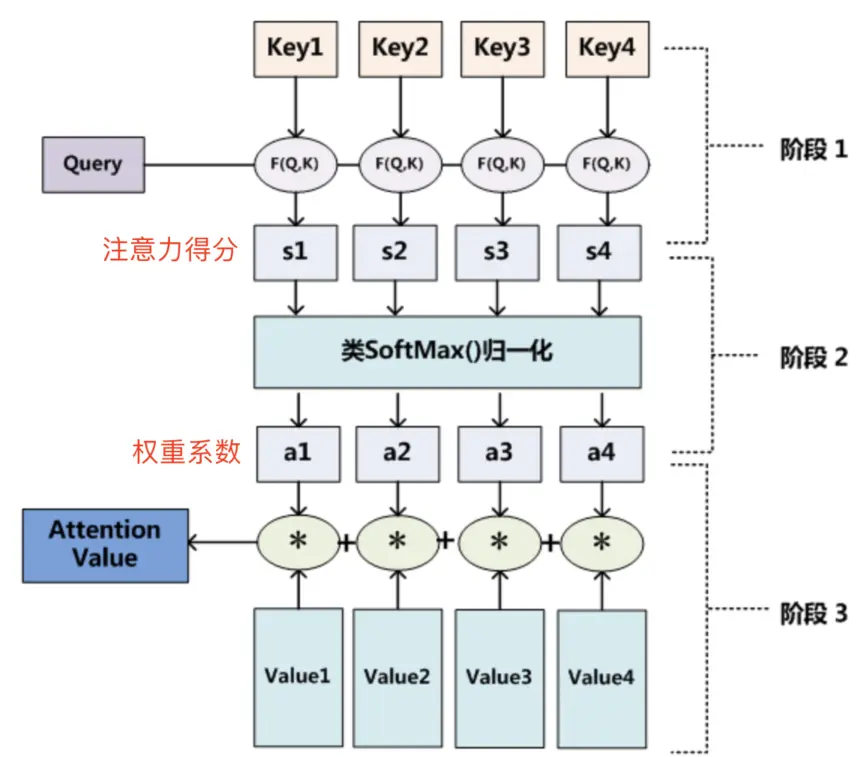
Attention机制引入了三个核心概念:Query (Q), Key (K), 和 Value (V)
- Query (Q): 代表当前的任务或焦点。在Decoder中,它通常是解码器上一步的隐藏状态,代表着“我接下来要生成什么词?”这个问题
- Key (K): 与输入序列中的每个元素相关联。它用于和Query进行匹配,以衡量该元素的重要性。可以理解为输入信息的“标签”
- Value (V): 也与输入序列中的每个元素相关联。它是该元素的实际内容。一旦通过Q-K匹配计算出权重,这个权重就会作用于V上
具体计算过程见上述链接图解参考材料
在经典的Encoder-Decoder架构中,Q来自Decoder,而K和V都来自Encoder的所有时间步的输出向量(通常K和V是同一个向量)
我们可以用一个生活中的例子来理解Attention:
场景:你在做一道阅读理解题
题目问:“主角在文章结尾时的心情是怎样的?”
你不会把整篇文章从头到尾等同地看一遍,然后凭记忆回答。你的做法更可能是:
- 带着问题(“主角结尾的心情”)去文章中寻找线索
- 你的目光会快速扫过不相关的段落,而在描述主角最后行为和心理活动的句子上重点关注
- 最后,你根据这些重点信息,综合得出答案
这个过程就是Attention。
- 问题 “主角结尾的心情” 就是查询(Query)
- 文章中的每一句话 都可以看作是信息键值对(Key-Value Pair),其中“键”是句子的概括,“值”是句子的具体内容
- 你将你的问题(Query)与文章中每句话的概括(Key)进行匹配,找到最相关的句子
- 你给予这些相关句子更高的权重(Attention Weight),并最终结合这些高权重的句子内容(Value)来得出答案
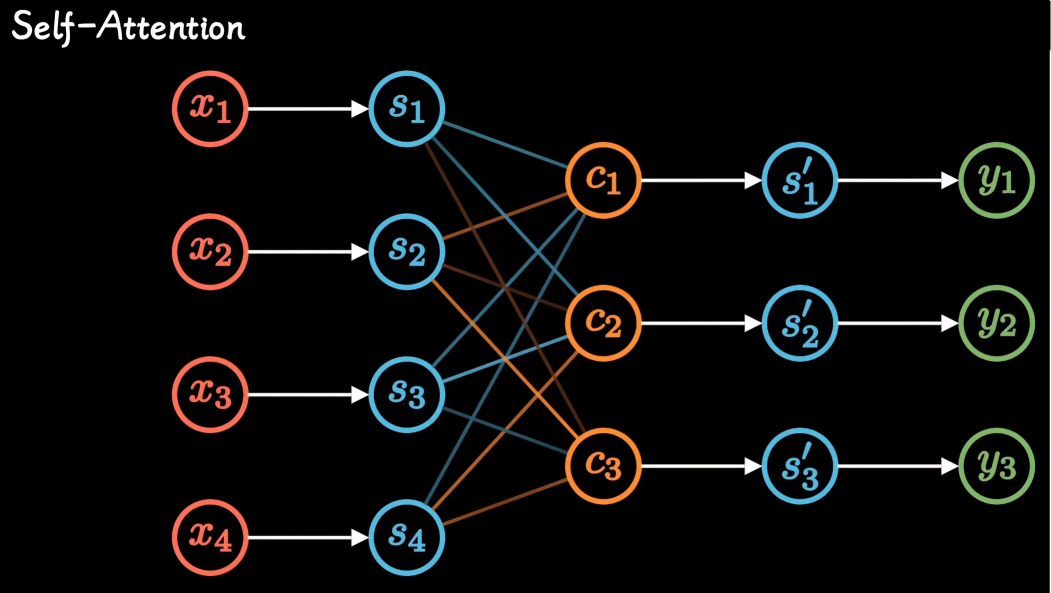
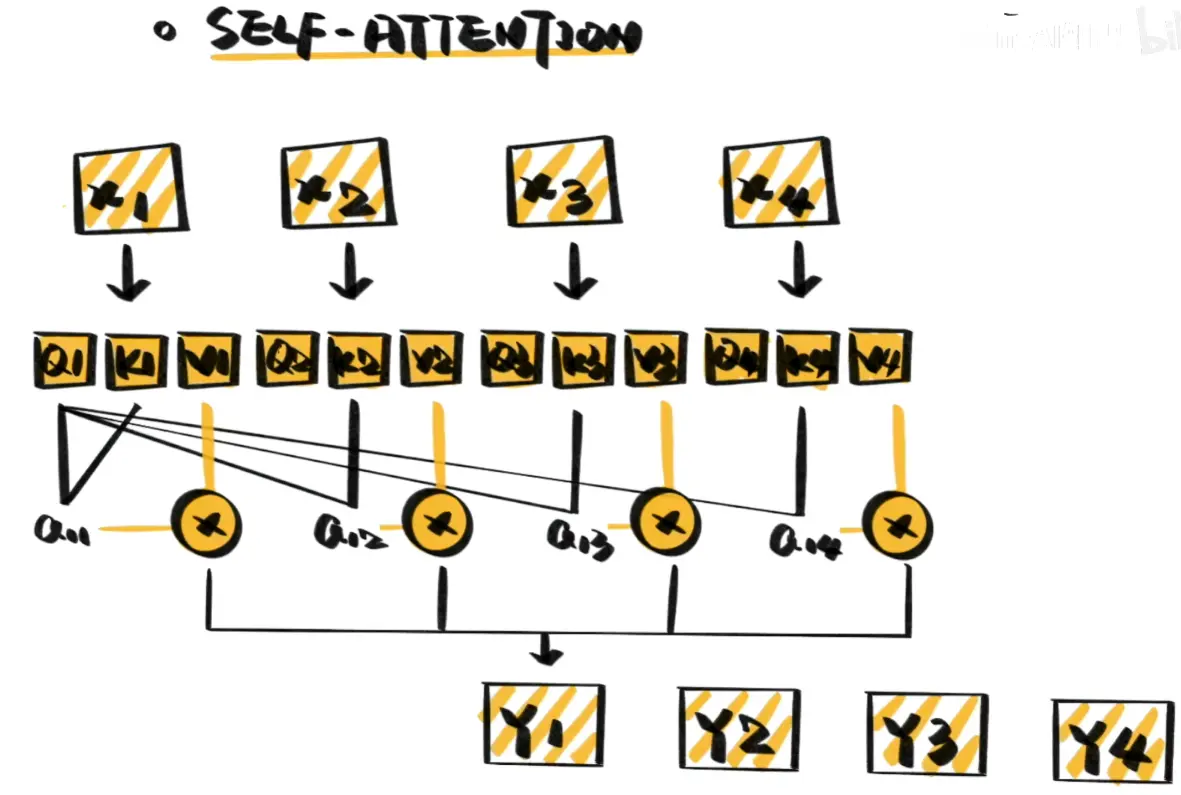
Self-Attention
self-attention只关注输入序列元素之间的关系,即每个输入元素都有它自己的Q、K、V,也方便了并行化计算
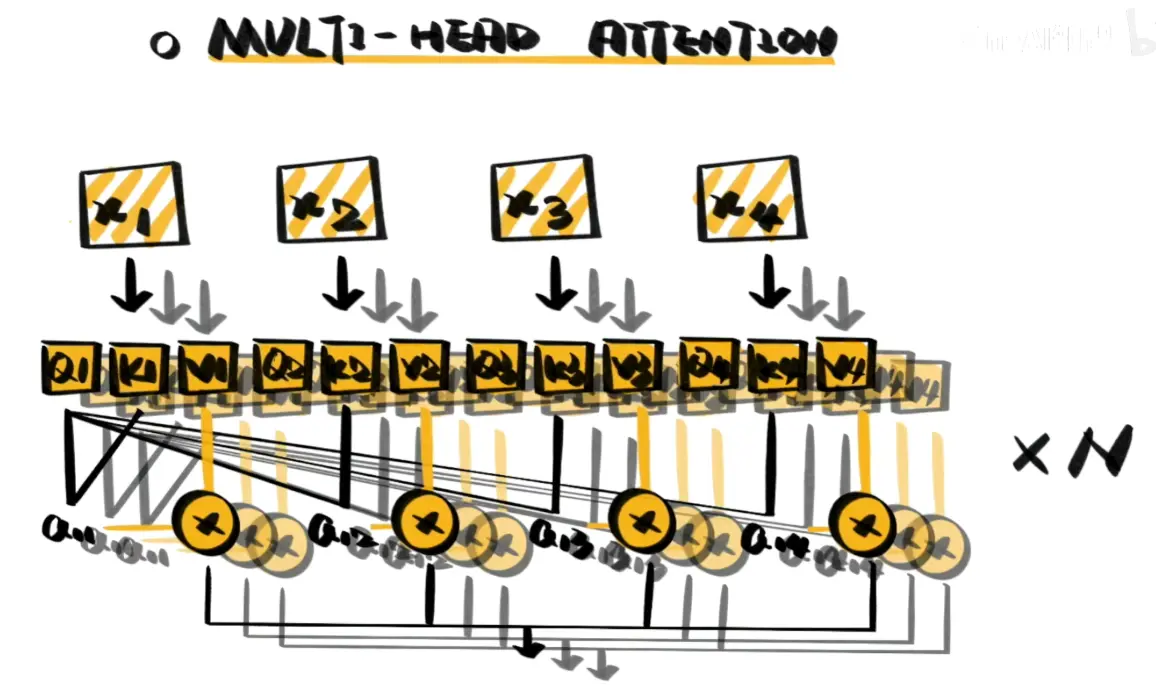
Mult-head Attention 多头注意力机制
在自注意力的基础上,使用多种变换生成的Q、K、V进行计算,即每层都有多组Q、K、V权重,叠加使用self-attention从而增强注意力效果
Transformer
Attention is All You Need !!
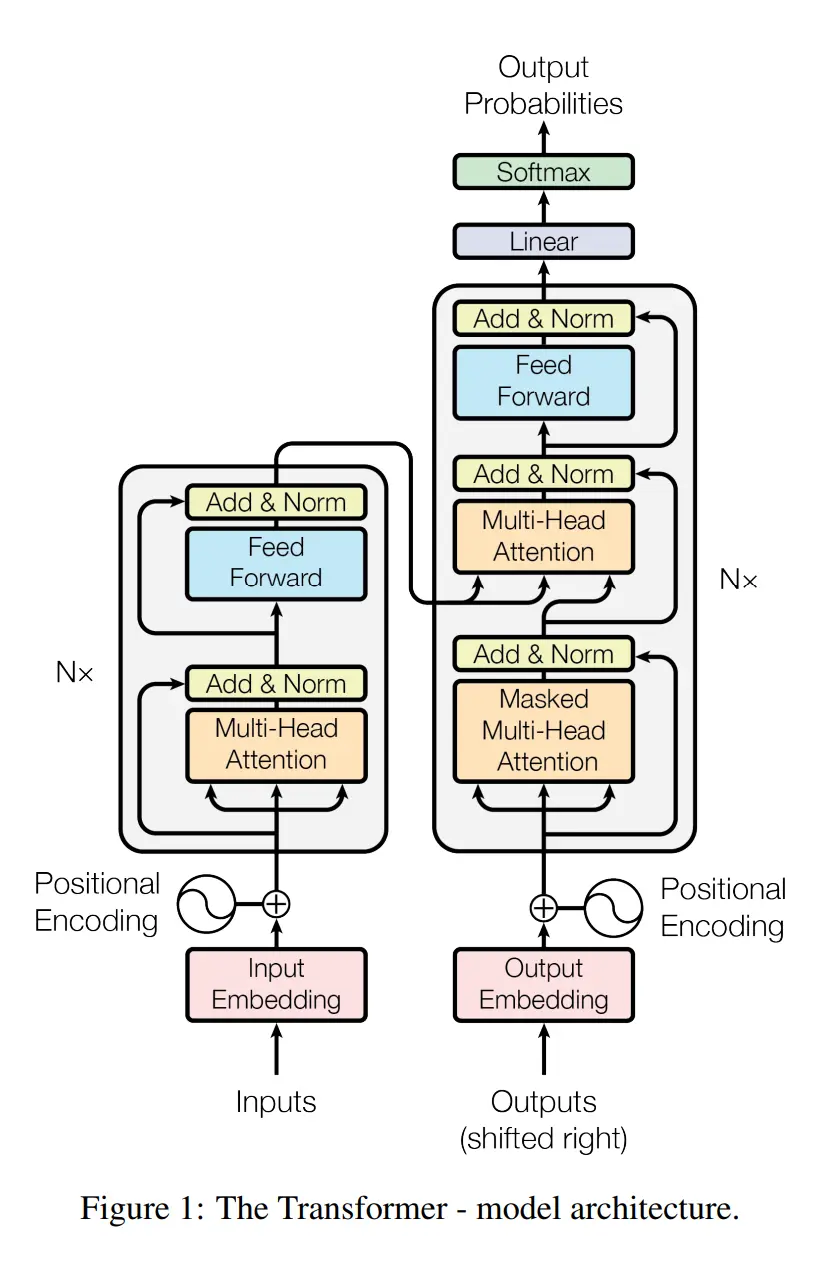
Transformer 遵循着一个常见于机器翻译等任务的 编码器-解码器 结构,左侧部分是编码器(Encoder),接收一个输入序列,并将其处理成一组富含上下文信息的连续表示;右侧部分是解码器(Decoder)它接收编码器的输出以及已经生成的部分输出序列,然后预测下一个词,循环往复,直到生成完整的输出序列
输入处理(Inputs & Outputs)
-
词嵌入(Input/Output Embedding)
计算机无法直接理解文本。因此,输入序列(Inputs)和输出序列(Outputs)中的每个单词首先需要通过一个词嵌入层转换成一个固定维度的向量。这个向量可以捕捉单词的语义信息 -
位置编码(Positional Encoding)
Transformer 的核心是自注意力机制(Self-Attention),它在处理单词时并不关心它们的顺序,这导致它本身无法理解句子中的语序信息(例如,“我打你”和“你打我”在它看来没有区别)
为了解决这个问题,模型引入了位置编码。这是一个与词嵌入向量维度相同的向量,它根据单词在序列中的绝对或相对位置生成。这个位置编码向量会直接加到对应的词嵌入向量上。这样,每个单词的最终表示就同时包含了其语义信息和位置信息
编码器(Encoder)
图中的编码器由一个包含了 N× 的堆栈组成,这意味着它是由 N 个完全相同的层堆叠而成的(在原论文中 N=6)。每一层都包含两个主要的子层:
1. 多头自注意力层(Multi-Head Attention)
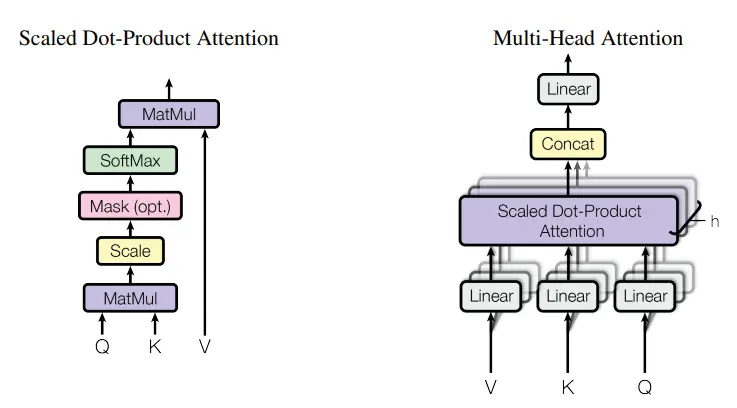
自注意力(Self-Attention):当编码器处理输入序列中的某个单词时,自注意力机制允许它去关注输入序列中的所有其他单词,并计算出每个单词对于当前单词的重要性(权重)。这使得模型能够根据上下文更好地理解单词的含义。例如,在句子 “The animal didn’t cross the street because it was too tired” 中,自注意力可以帮助模型理解 “it” 指的是 “The animal”
多头(Multi-Head):模型不会只进行一次注意力计算,而是将词向量投影到多个不同的“表示子空间”中(不同QKV),即在一个transformer层中有多组QKV权重,并行地计算多次注意力,这就是所谓的“多头”。这就像是用不同的视角去审视句子,有的头可能关注句法关系,有的头可能关注语义关系。最后,将所有头的注意力结果拼接并再次进行线性变换,得到最终的输出。这增强了模型捕捉不同方面信息的能力
2. 前馈神经网络(Feed-Forward Network, FFN)
这是一个简单的、逐位置的全连接前馈网络。它接收自注意力层的输出,并对其进行一次非线性变换。这个网络在所有位置上都是独立且相同的。它的作用可以被看作是进一步处理和提炼自注意力层输出的信息
在 Transformer 的注意力层(Attention)处理完一句话后,它为每个词生成了一个新的向量。这个向量融合了句中其他所有词的上下文信息。比如,对于句子“我把苹果吃了”,注意力层已经让“苹果”这个词的向量“知道”了它和“吃”这个动作有关
但是,这些信息还是混合在一起的。前馈神经网络(FFN)的作用就像一个“信息加工站”。它接收这个富含上下文的向量,然后对其进行一次更复杂的加工和提炼
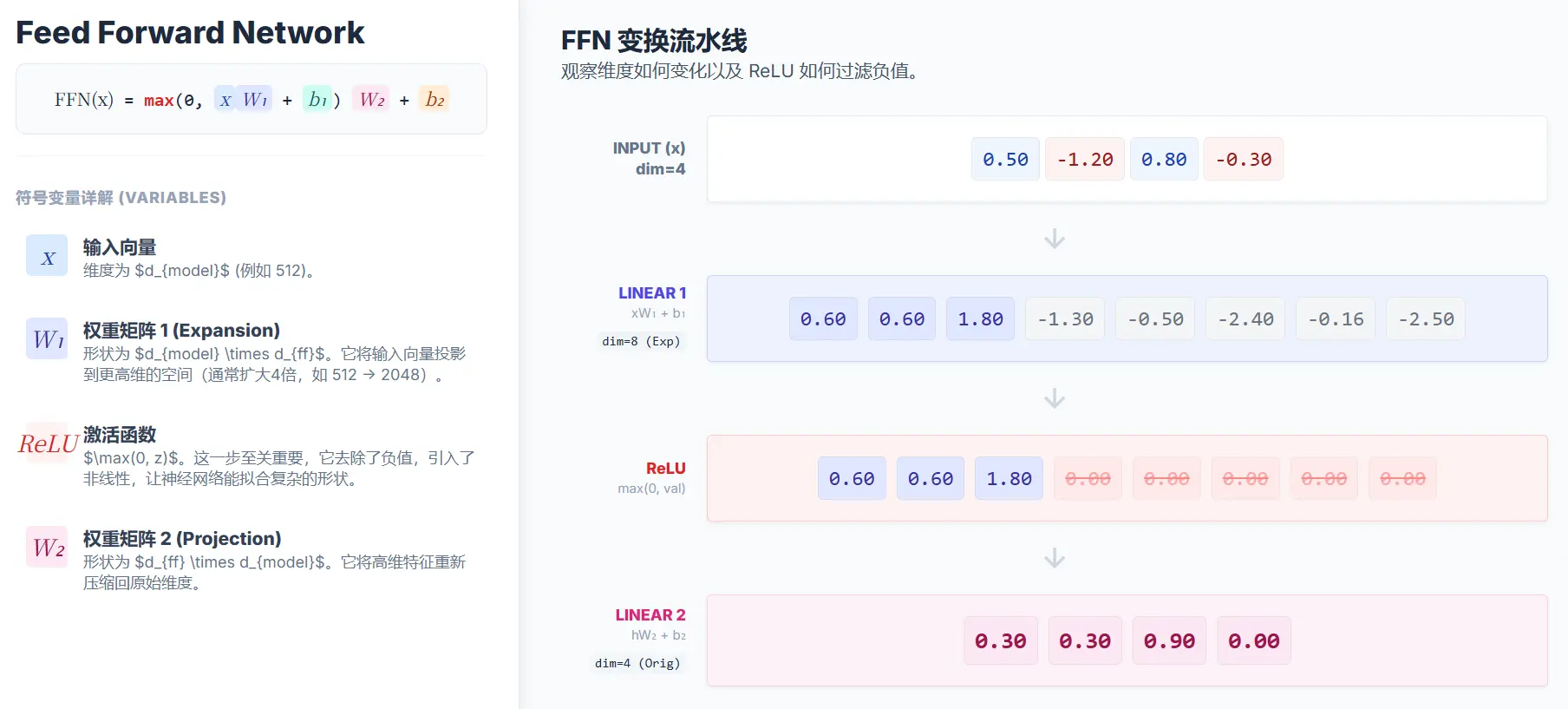
这个“加工站”内部有两道工序,对应着两个线性层(Linear layers)
- 第一道工序(扩展): 它首先将输入的向量“放大”。比如,一个 512 维的向量输入后,通过这个工序可能会变成一个 2048 维的向量。这个“放大”的过程可以理解为给了模型更多的空间去识别和分离输入信息中各种潜在的特征组合
- 非线性激活(ReLU): 在两道工序之间,会经过一个叫做 ReLU 的步骤。你可以把它想象成一个“过滤器”,它会丢弃掉所有的负数信息,只保留正数。这个简单的操作至关重要,因为它为模型引入了非线性,使得模型能够学习比简单线性关系更复杂的模式。没有它,再深的网络也只相当于一个简单的线性模型
- 第二道工序(收缩): 接着,它将这个被放大和过滤后的 2048 维向量再“压缩”回原来的 512 维
关键点:
- 逐个处理:这个 FFN 是独立地应用在序列中每一个词的向量上的。处理“苹果”这个词的 FFN 和处理“吃”这个词的 FFN,它们的内部参数(即工序中使用的工具)是完全相同的,但它们是分开、并行处理的,互不干扰
- 目的:FFN 的主要目的是对注意力层输出的信息进行进一步的非线性变换,增加模型的表示能力,帮助模型学习到更复杂的特征
简单来说,如果说注意力层(Attention)是负责“融合上下文信息”,那么前馈网络(FFN)就是负责对这些融合后的信息进行“深度加工和提炼”
3. Add & Norm(残差连接与层归一化)
在每个子层(多头注意力和前馈网络)的外面,都有一个 “Add & Norm” 的操作
Add(残差连接):这是指将子层的输入 x 直接加到子层的输出 Sublayer(x) 上,即 x + Sublayer(x),这种设计可以有效防止在深层网络中出现梯度消失的问题,让网络更容易训练
Norm(层归一化, Layer Normalization):在相加之后,对结果进行层归一化,这有助于稳定训练过程,加速收敛
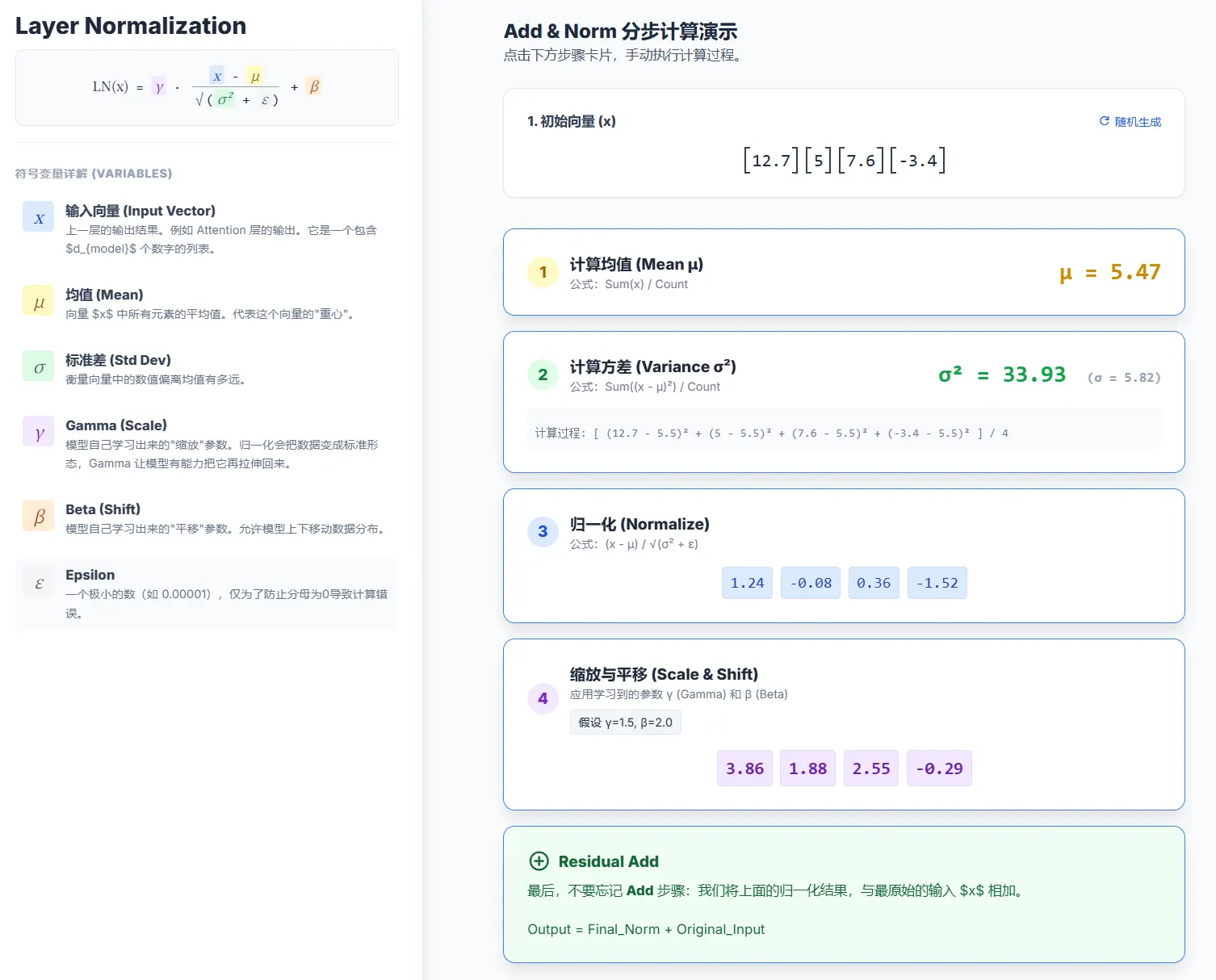
解码器(Decoder)
解码器同样由 N 个相同的层堆叠而成。每一层除了包含编码器中的两个子层外,还额外增加了一个子层,总共有三个主要子层
1. 掩码多头自注意力层(Masked Multi-Head Attention)
这一层与编码器中的自注意力层类似,但有一个关键区别:掩码(Masking)。 在生成(或训练)过程中,解码器需要根据已经生成的词来预测下一个词。为了防止模型在预测位置 i 的词时“偷看”到位置 i 之后(即未来)的词,需要将这些未来的词信息给遮盖掉。这就是“掩码”的作用,它确保了模型的预测只依赖于已知的历史输出
2. 编码器-解码器注意力层(Encoder-Decoder Attention)
这是连接编码器和解码器的桥梁。在这一层里,它的查询(Query)来自于前一个解码器子层(即掩码自注意力层)的输出,而它的键(Key)和值(Value)则来自于编码器的最终输出
这一步允许解码器在生成每个词时,能够关注到输入序列中的所有位置,并从中提取最相关的信息。例如,在翻译任务中,当要生成一个法语动词时,解码器会通过这个机制重点关注输入英文句子中的对应动词和主语
3. 前馈神经网络(Feed Forward)
这与编码器中的前馈网络完全相同,作用也一样
同样,解码器的每个子层也都包裹着 Add & Norm 结构
最终输出层(Final Output)
解码器堆栈的最终输出是一个浮点数向量。为了得到最终的预测单词,还需要经过两个步骤:
- 线性层(Linear):一个简单的全连接神经网络,它将解码器输出的向量投影到一个非常大的向量上,这个向量的维度等于词汇表的大小。这个大向量被称为 logits 向量
- Softmax 层:Softmax 函数会将 logits 向量转换成一个概率分布。向量中的每个值都对应词汇表中的一个单词,表示该单词是下一个输出词的概率。通常,我们会选择概率最高的那个单词作为最终的输出
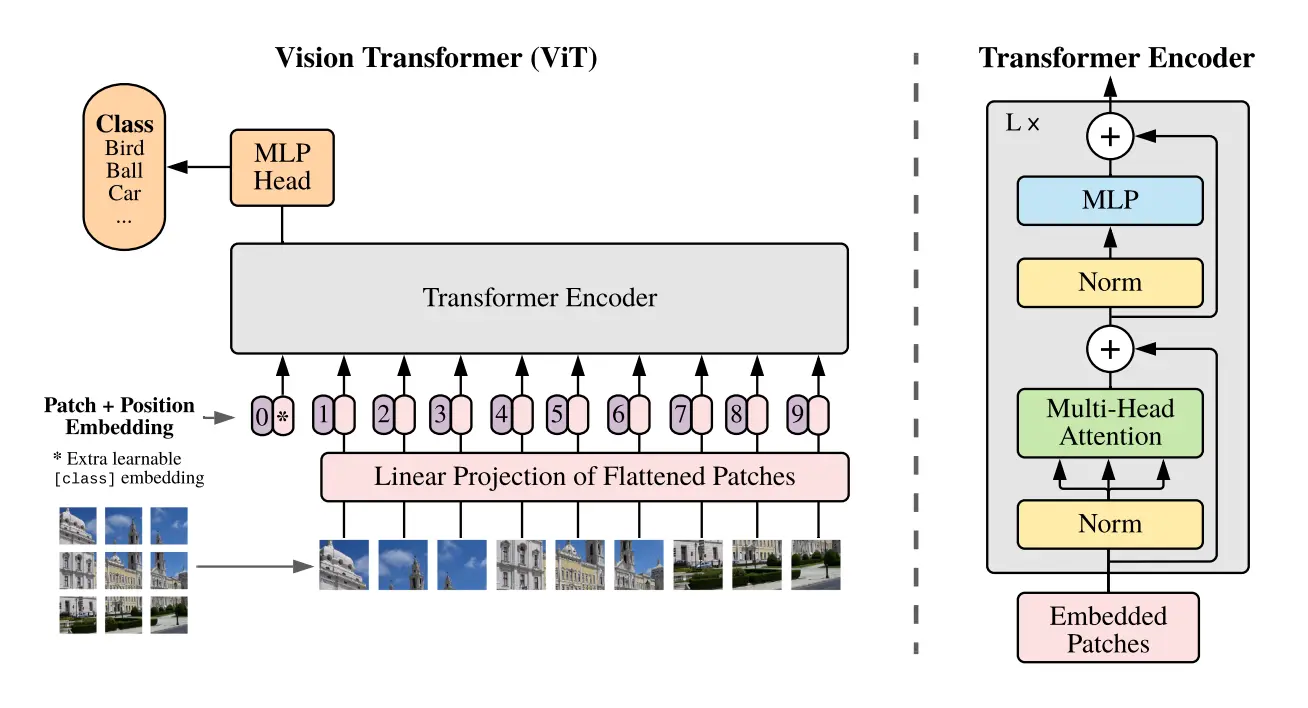
ViT
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
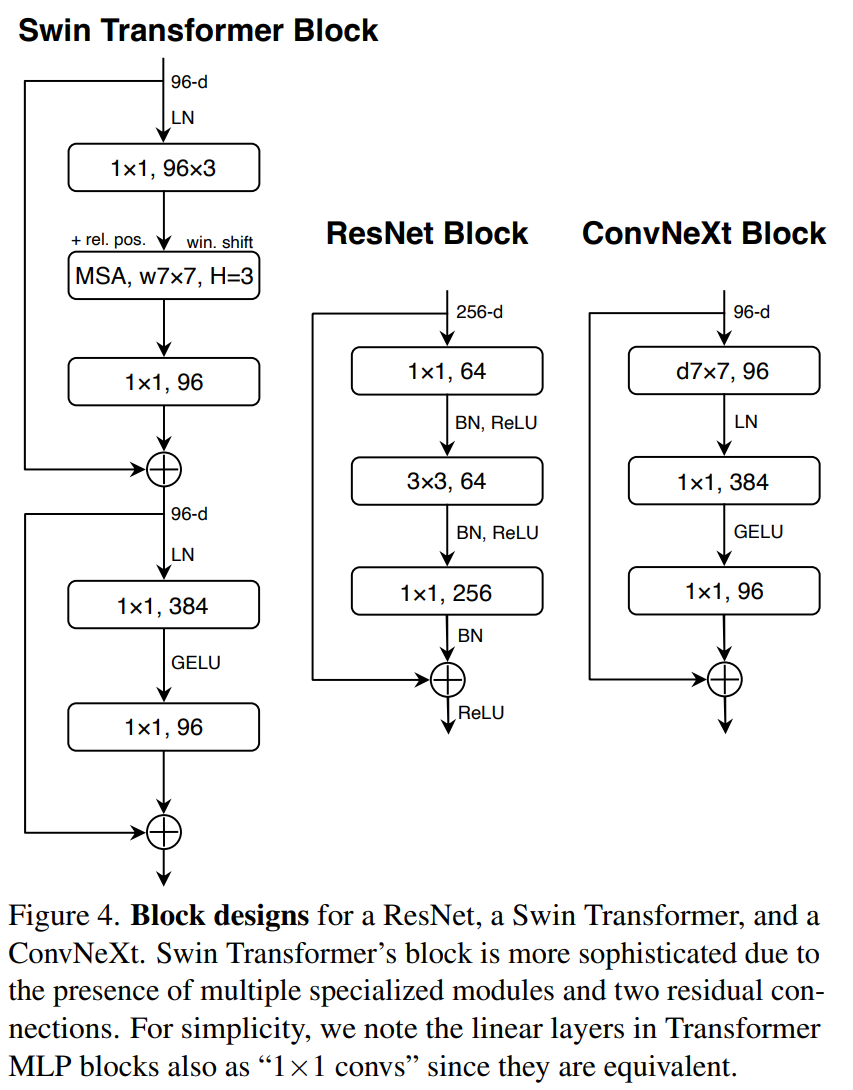
ConvNeXt
A ConvNet for the 2020s
ConvNext v2
Co-designing and Scaling ConvNets with Masked Autoencoders
CLIP
Learning Transferable Visual Models From Natural Language Supervision
模型大小
| name | params (M) | FLOPs (B) |
|---|---|---|
| ViT Models | ||
| ViT-L-14-336 | 427.94 | 395.22 |
| ViT-L-14 | 427.62 | 175.33 |
| ViT-B-16 | 149.62 | 41.09 |
| ViT-B-32 | 151.28 | 14.78 |
| ResNet Models | ||
| RN50x64 | 623.26 | 552.65 |
| RN50x16 | 290.98 | 162.69 |
| RN50x4 | 178.3 | 51.82 |
| RN101 | 119.69 | 25.5 |
| RN50 | 102.01 | 18.18 |
数据来源:OpenClip的基准测试
核心架构组件
图像编码器 (Image Encoder):
- 作用:将输入的图像转换成一个数学向量(特征嵌入),这个向量代表了图像的内容
- 具体模型:论文中测试了两种主流的架构 :
- ResNet-50:一个经过改进的经典卷积神经网络(CNN)
- Vision Transformer (ViT):一种更新的、基于 Transformer 的架构
文本编码器 (Text Encoder):
- 作用:将输入的文本片段转换成一个数学向量(特征嵌入),这个向量代表了文本的语义
- 具体模型:一个标准的 Transformer 模型 。它使用一个大小为 49,152 的词汇表,并将文本序列的最大长度限制在 76 个词元(tokens)
这两个编码器将图像和文本映射到一个共享的、多模态的嵌入空间中,使得相似概念的图像和文本在空间中的位置彼此靠近
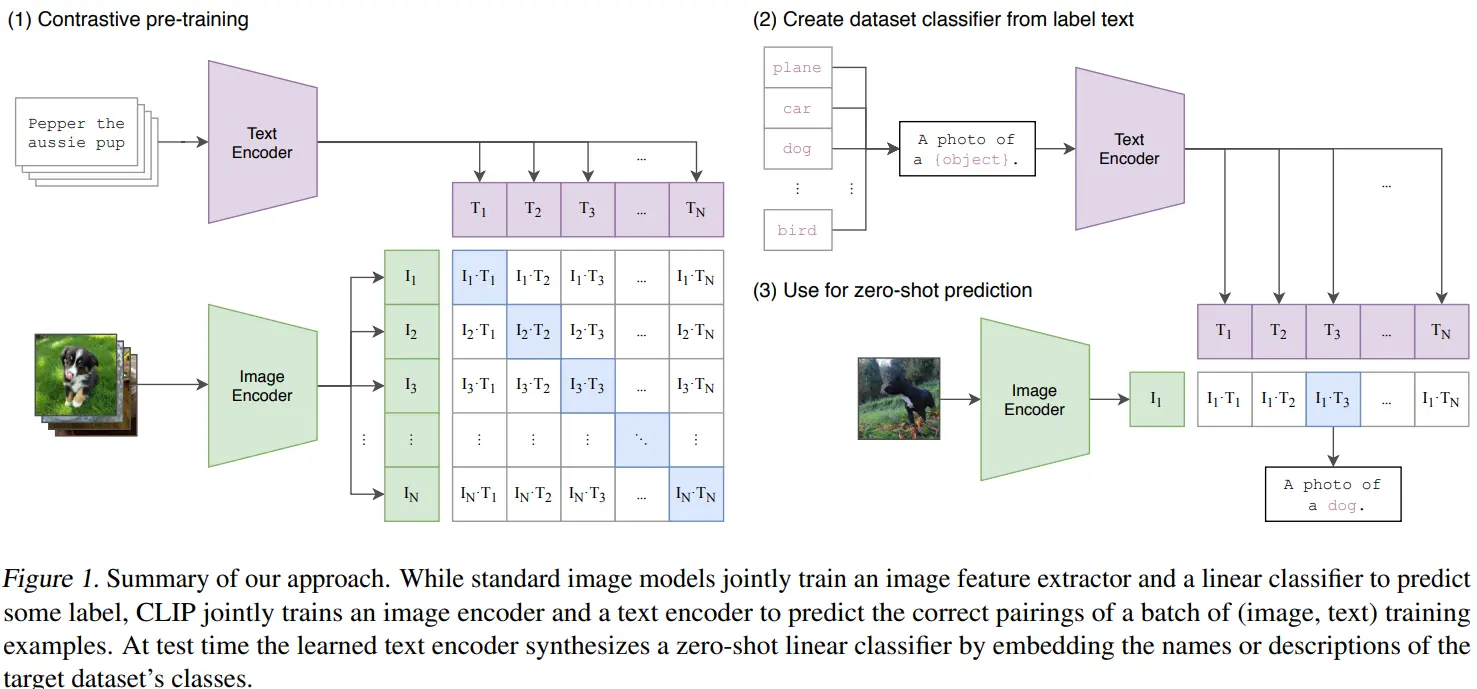
训练过程:对比式预训练 (Contrastive Pre-training)
训练数据:OpenAi收集了400 million 的数据文本对,称为WIT(私有数据集)
对比学习具体步骤如下:
-
构建批次 (Batch):从数据集中随机抽取一批
N个 (图像, 文本) 对 。例如,(图片A, “描述A”),(图片B, “描述B”),…,(图片N, “描述N”) -
分别编码:
N张图像被送入图像编码器,生成N个图像特征向量 (I1,I2,…,IN)N段文本被送入文本编码器,生成N个文本特征向量 (T1,T2,…,TN)
-
计算相似度:模型会计算这批次中所有可能的图像-文本对的相似度。对于
N个图像和N个文本,总共有 N×N 种可能的配对组合 。相似度是通过计算图像向量和文本向量之间的余弦相似度来度量的 -
学习目标:
- 最大化
N个正确配对(对角线上的 I1⋅T1, I2⋅T2 等)的余弦相似度 - 最小化
N2−N个错误配对(所有非对角线上的组合,如 I1⋅T2, I2⋅T1 等)的余弦相似度
- 最大化
应用:零样本预测 (Zero-Shot Prediction)
- 拿来一张新的、需要分类的图片(例如,一张狗的图片)
- 将这张图片送入已经训练好的图像编码器,生成一个图像特征向量
- 计算这个图像向量与文本经过文本编码器得到的文本向量(“A photo of a dog.”, “A photo of a cat.” 等)的余弦相似度
- 相似度分数最高的那个文本提示所对应的类别,就是模型的最终预测结果
CLIP4Clip
CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
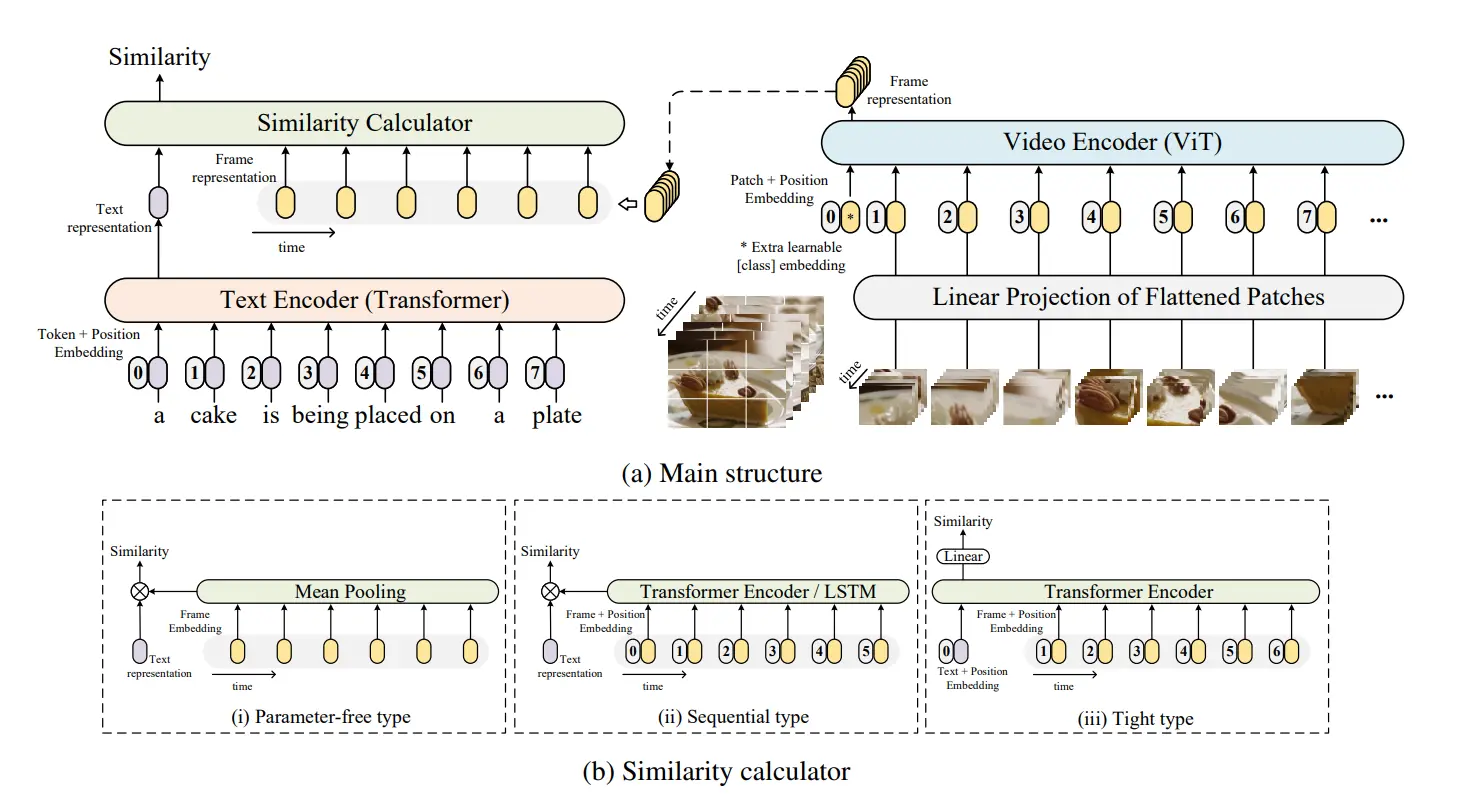
核心架构组件
- 文本编码器 (Text Encoder) - 基本不变
这一部分与原始的 CLIP 架构完全相同
-
模型:直接采用 CLIP 预训练好的 Transformer 文本编码器
-
功能:输入一段文字描述,输出一个代表该文字语义的单一特征向量 (wj)
- 视频编码器 (Video Encoder) - 从单帧到序列
这是第一个关键的改造点:CLIP 的图像编码器一次只能处理一张图片,而视频是连续的帧序列。
CLIP4Clip 的处理方式是:
-
模型骨干:同样直接采用 CLIP 预训练好的图像编码器 (ViT-B/32)
-
处理流程:
-
帧采样:从输入的视频中,首先采样出一系列有序的帧(即多张图片)
-
逐帧编码:将这些帧一张一张地送入 ViT 图像编码器
-
序列输出:最终,视频编码器输出的不再是像 CLIP 那样的一个向量,而是一个特征向量的序列 (
Zi={zi1,zi2,...,zi∣vi∣}) 。序列中的每一个向量都代表了视频中对应帧的内容
-
核心区别:CLIP 处理图片输出一个向量,CLIP4Clip 处理视频输出一串向量
- 相似度计算器 (Similarity Calculator) - 核心创新
如何比较一个“文本向量”和一串“视频帧向量”,并得出一个最终的相似度分数?这是 CLIP4Clip 架构最核心的创新和研究点。论文提出了三种不同的策略来解决这个问题:
策略 A: 无参数类型 (Parameter-free type)
这种方法最简单,完全依赖 CLIP 预训练好的能力,不引入任何新的学习参数
当数据集较小时效果最好,因为在小型数据集上,引入新的、未初始化的参数(如序列类型中的 LSTM 或 Transformer)很难被有效训练,反而可能会损害从 CLIP 预训练模型中继承来的强大性能
- 工作方式:
- 通过平均池化 (Mean Pooling) 将视频的所有帧特征向量聚合成一个能代表整个视频的“平均特征向量”
- 计算这个“平均视频向量”和“文本向量”之间的余弦相似度,作为最终得分
- 可以理解为:把视频的所有精彩瞬间“平均”成一张综合的“代表图”,再用 CLIP 的方式去和文本匹配
策略 B: 序列类型 (Sequential type)
这种方法认为视频帧的顺序很重要,不能简单求平均
当数据集足够大时,模型才有能力去学习序列类型中引入的额外参数,从而更好地捕捉视频的帧间时序关系
-
工作方式:
- 在求平均之前,先将视频帧的特征序列送入一个序列模型(如 LSTM 或 Transformer Encoder),这个模型会学习帧与帧之间的时间依赖关系,输出一组包含了时序信息的新特征序列
- 再对这组新的特征序列进行平均池化,最后计算余弦相似度
-
可以理解为:先“看完”整个视频的故事线(捕捉时序信息),形成一个整体理解,再用这个整体理解去和文本匹配
策略 C: 紧密类型 (Tight type)
这种方法最为复杂,它试图让文本和视频的特征进行深度的跨模态融合
实际效果最差,紧密类型引入了最多的新参数来进行跨模态交互,在没有足够数据的情况下,这个模块很难被有效学习
- 工作方式:
- 将文本特征向量和视频帧的特征序列直接拼接 (concatenate) 在一起,形成一个统一的长序列
- 将这个混合序列送入一个全新的 Transformer Encoder 中,让文本和视频的特征在内部充分交互、相互影响
- 最后通过一个线性层直接预测出相似度分数
- 可以理解为:让文本和视频的每一帧进行“对话和协商”,共同决定它们的匹配程度
XCLIP
X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval
- 论文地址:hhttps://arxiv.org/pdf/2207.07285
- 代码仓库:https://github.com/xuguohai/X-CLIP
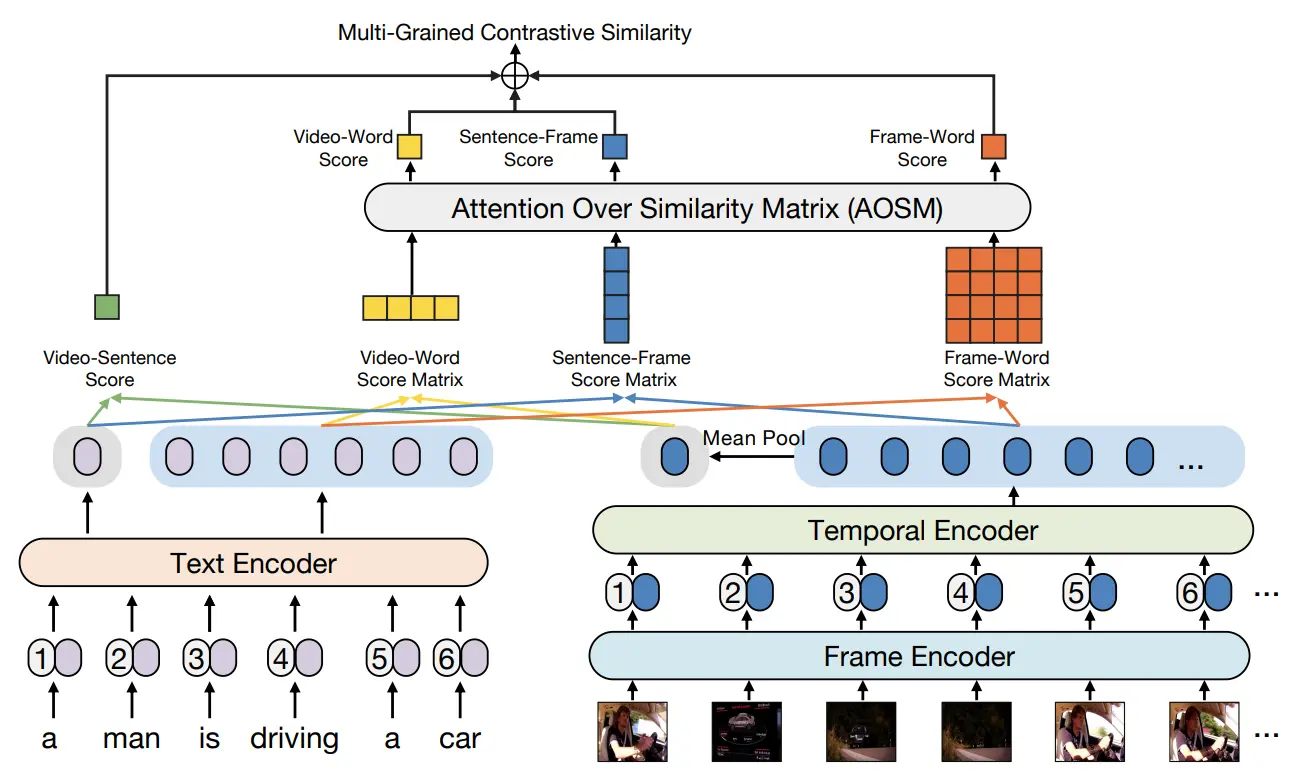
模型架构
TeachCLIP
Holistic Features are almost Sufficient for Text-to-Video Retrieval
- 论文地址:https://openaccess.thecvf.com/content/CVPR2024/papers/Tian_Holistic_Features_are_almost_Sufficient_for_Text-to-Video_Retrieval_CVPR_2024_paper.pdf
- 代码仓库:https://github.com/ruc-aimc-lab/TeachCLIP?tab=readme-ov-file
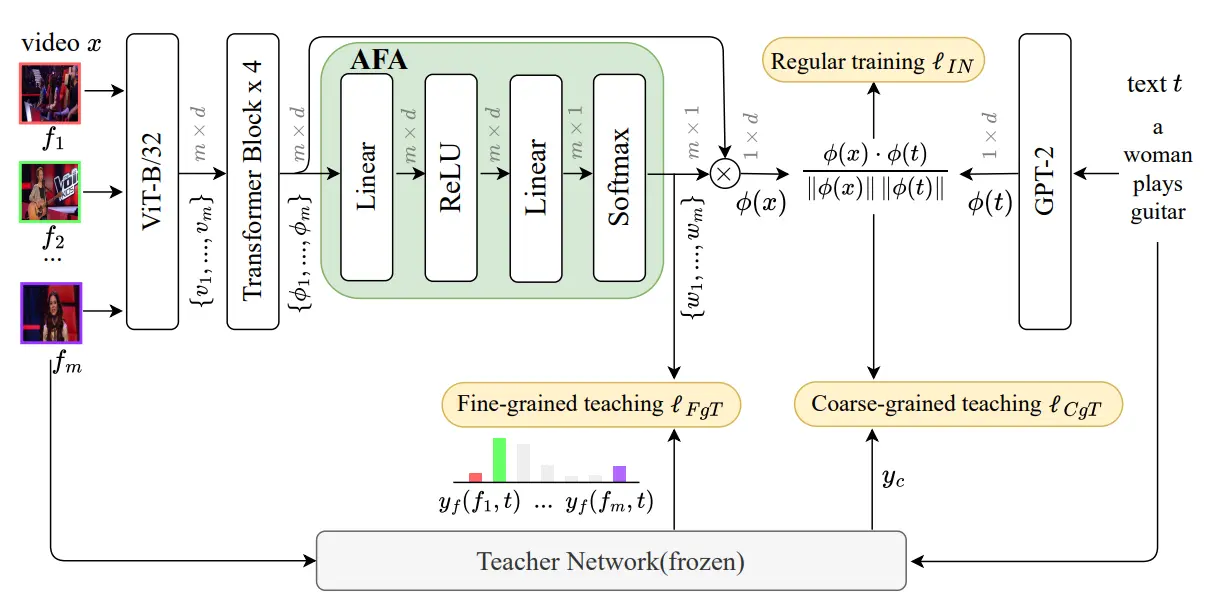
模型架构
Backbone: CLIP(ViT-B/32) 或 CLIP(ViT-B/16)
The key data flow of the visual side of the student network is expressed as follows:
Loss组成
- (常规训练损失)
与Clip中相同,跨模态匹配中的标准训练损失。目标是拉近匹配的视频-文本对的相似度,推远不匹配的视频-文本对的相似度
- (视频级粗粒度教学损失)
最小化学生和教师网络输出之间的皮尔逊距离 (或等效地,最大化皮尔逊相关系数),使学生能够模仿教师输出排序。因此选择使用 作为粗粒度教学损失 。对于视频 ,损失计算为
- 是 softmax
- :代表学生网络计算的相似度矩阵的第 行。它表示的是第 个视频 与批次中所有文本 的相似度分数向量
- :代表教师网络计算的第 个视频 与批次中所有文本的相似度分数向量
以类似的方式,文本 的损失计算为
因此, 定义为以下批次级别的对称损失:
- (帧级细粒度教学损失)
在帧级别进行监督,论文为学生网络增加了一个“注意力帧特征聚合 (AFA)”模块,该模块会为视频的每一帧生成一个注意力权重 ,教师网络会提供每个单独的帧 与文本 之间的相关性分数 (可以理解为教师给出的帧权重)。 通过计算学生AFA模块生成的帧权重 与教师提供的帧-文本相似度 (作为软标签) 之间的**交叉熵损失 (Cross-Entropy, CE) **来实现。直观上,如果教师认为某一帧很重要,学生网络也应该为该帧分配更高的权重
- :就是老师给的权重
- :就是学生给的权重
- :学生越不自信( 越小, 越负),惩罚越大
- :交叉熵的核心。如果 很大(老师说很重要)而 很小(学生说不重要), 是一个很大的负数,再乘上 和公式前面的负号,就变成一个巨大的正损失
关于交叉熵与KL散度的区别见文末
帧间注意力聚合
杂鱼 ❤~
交叉熵与KL散度
交叉熵公式:
KL 散度公式:
展开对数除法:
拆分成两项:
在教师网络冻结的前提下,对于优化器来说,KL 散度和交叉熵没有实质性区别
优化器(SGD/Adam)只看梯度(导数),不看 Loss 的绝对值
求导(针对学生参数 ):
关键点:因为教师网络是冻结的,教师的分布 是固定的,所以 是一个常数。常数的导数为 0。
结论:不管你选哪个,传回给学生网络的更新信号(梯度向量)是完全重合的。
在 PyTorch 或 TensorFlow 中,交叉熵损失(Cross Entropy Loss, CE)针对 Logits()的梯度公式非常简洁:
- :学生模型输出的 Logit(Softmax 之前的值)
- :学生模型输出的概率()
- :教师模型给出的目标概率