CS307 Principles of Database Systems
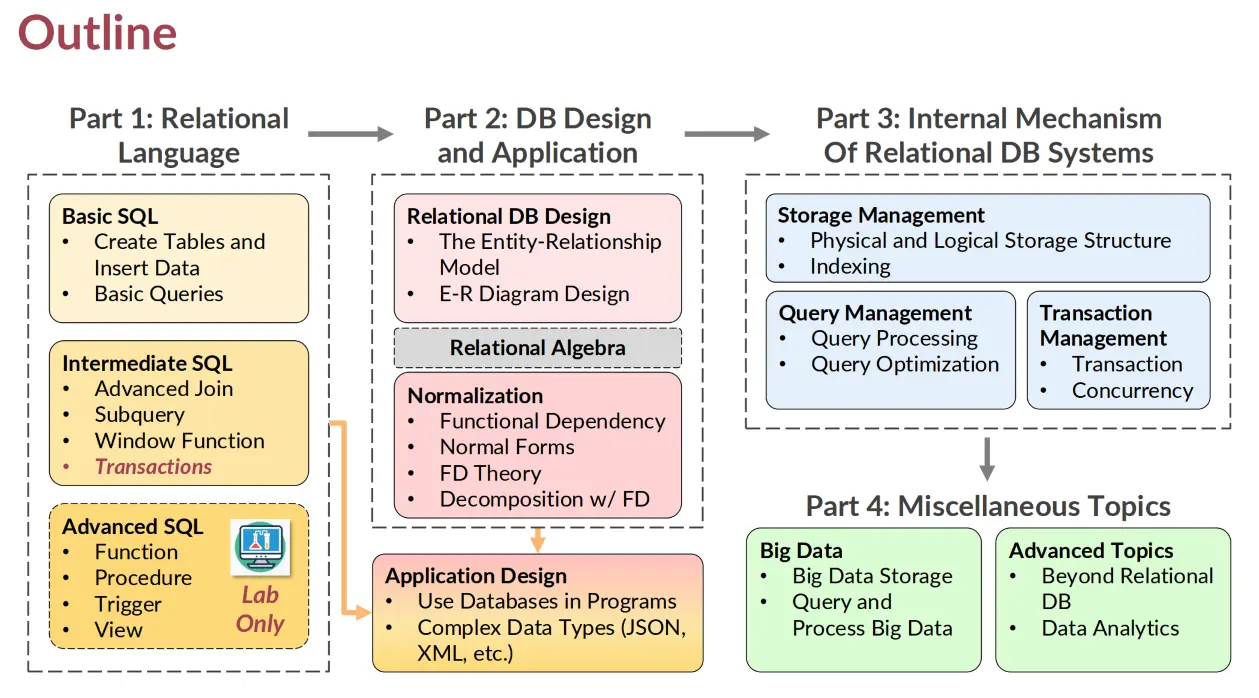
SQL
DDL 数据定义语言
DDL 用于构建和管理数据库的结构
CREATE DATABASE
用于创建一个新的数据库
语法:
1 | |
DROP DATABASE
用于删除一个已存在的数据库。这是一个不可逆的操作
语法:
1 | |
CREATE TABLE
用于在当前数据库中创建一个新表。这是最核心的 DDL 语句之一
语法:
1 | |
- 常用数据类型 (datatype):
INTEGER或INT: 整数BIGINT: 大整数SERIAL: 自增整数,常用于主键NUMERIC(precision, scale): 精确的十进制数VARCHAR(n): 可变长度的字符串TEXT: 无长度限制的文本BOOLEAN: 布尔值 (true或false)DATE: 日期TIME: 时间TIMESTAMP或TIMESTAMPTZ: 时间戳(带或不带时区)JSONB: 二进制格式的 JSON 数据,效率更高
- 常用约束 (constraints):
NOT NULL: 该列不允许为 NULLUNIQUE: 该列的值必须唯一PRIMARY KEY: 主键,唯一标识表中的每一行(自带NOT NULL和UNIQUE属性)FOREIGN KEY: 外键,用于关联另一张表CHECK: 检查列中的值是否满足特定条件DEFAULT: 为列设置默认值
示例:
1 | |
ALTER TABLE
用于修改现有表的结构
语法和示例:
-
添加列:
1
ALTER TABLE employees ADD COLUMN department VARCHAR(50); -
删除列:
1
ALTER TABLE employees DROP COLUMN department; -
修改列的数据类型:
1
ALTER TABLE employees ALTER COLUMN first_name TYPE TEXT; -
添加约束:
1
ALTER TABLE employees ADD CONSTRAINT email_unique UNIQUE (email); -
删除约束:
1
ALTER TABLE employees DROP CONSTRAINT email_unique;
DROP TABLE
删除一个表及其所有数据
语法:
1 | |
TRUNCATE TABLE
快速删除一个表中的所有行,但保留表结构。比 DELETE 语句更快,且不会触发 DELETE 触发器
语法:
1 | |
DML 数据操作语言
DML 用于管理表中的数据
INSERT INTO
向表中插入新的行(记录)
语法:
1 | |
示例:
1 | |
UPDATE
修改表中的现有记录。强烈建议始终与 WHERE 子句一起使用,否则将更新表中的所有行!
语法:
1 | |
示例:
1 | |
DELETE FROM
从表中删除记录。强烈建议始终与 WHERE 子句一起使用,否则将删除表中的所有行!
语法:
1 | |
示例:
1 | |
DQL 数据查询语言
DQL 用于从数据库中检索信息,是使用最频繁的部分
SELECT
从表中查询数据
基本语法:
1 | |
常用子句和示例:
-
查询所有列:
1
SELECT * FROM employees; -
DISTINCT- 去重查询:1
2-- 返回所有不重复的部门名称
SELECT DISTINCT department FROM employees; -
WHERE- 条件过滤:1
2
3
4
5
6
7
8
9
10
11
12
13
14-- 使用比较运算符 (=, >, <, !=, >=, <=)
SELECT first_name, salary FROM employees WHERE salary > 50000;
-- 使用 AND, OR, NOT 组合条件
SELECT * FROM employees WHERE department = 'Sales' AND salary > 60000;
-- 使用 IN 匹配多个值
SELECT * FROM employees WHERE department IN ('Sales', 'Marketing');
-- 使用 BETWEEN 指定范围
SELECT * FROM employees WHERE hire_date BETWEEN '2023-01-01' AND '2023-12-31';
-- 使用 LIKE 进行模糊匹配 (% 代表任意多个字符, _ 代表单个字符)
SELECT * FROM employees WHERE email LIKE '%@example.com'; -
ORDER BY- 排序:1
2-- ASC: 升序 (默认), DESC: 降序
SELECT first_name, salary FROM employees ORDER BY salary DESC; -
LIMIT和OFFSET- 分页:1
2
3
4
5-- 获取前10条记录
SELECT * FROM employees LIMIT 10;
-- 跳过前10条,获取接下来的5条
SELECT * FROM employees LIMIT 5 OFFSET 10;
聚合函数 (Aggregate Functions)
GROUP BY 分组统计:
- 常用函数:
COUNT(),SUM(),AVG(),MAX(),MIN()
1 | |
-
HAVING- 对分组后的结果进行过滤:1
2
3
4
5
6
7-- 找出平均工资超过 70000 的部门
SELECT
department,
AVG(salary) AS average_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 70000;
窗口函数 (Window Functions)
窗口函数也用来完成分组统计,与聚合函数不同,窗口函数不会折叠行。它在保留原始行的同时加 Columns,计算基于特定“窗口”(一组相关行)的值。常用于排名、累计求和、移动平均等
核心语法: 函数名() OVER (PARTITION BY 分组列 ORDER BY 排序列)
常用函数:
- 聚合类:
SUM(),AVG(),MAX(),MIN()(作为窗口函数使用时,计算的是窗口内的统计值) - 排名类:
ROW_NUMBER(): 连续排名,唯一 (1, 2, 3, 4)RANK(): 跳跃排名,并列 (1, 2, 2, 4)DENSE_RANK(): 连续排名,并列 (1, 2, 2, 3)- 偏移类:
LAG(col, n): 当前行往前第 n 行的值 (常用于计算环比)LEAD(col, n): 当前行往后第 n 行的值
示例:
1 | |
JOIN
JOIN用来连接多个表,假设我们有另一个 departments 表:
1 | |
INNER JOIN(内连接): 返回两个表中匹配的行(交集)
1 | |
普通 JOIN 是 INNER JOIN
LEFT JOIN(左连接): 返回左表的所有行,以及右表中匹配的行(右表不匹配的行用 NULL 填充)
1 | |
-
Right JOIN(右连接): 与左连接同理,返回右表的所有行,以及左表中匹配的行(右表不匹配的行用 NULL 填充) -
FULL OUTER JOIN(全外连接):它会返回左表和右表中的所有行。当某一行在另一个表中没有匹配时,另一个表的列将显示为NULL(并集)
1 | |
AS- 别名: 为表或列提供一个临时的名称,使查询更易读。上面的e和d就是表的别名
UNION
用于将两个或多个
SELECT语句的结果集合并为一个结果集
UNION: 合并结果集并去重(会有排序/哈希开销,速度较慢)UNION ALL: 直接拼接结果集,不去重(性能更高,推荐默认使用)
语法:
1 | |
WITH
用于定义一个临时的结果集,可以在主查询中多次引用。主要用于简化复杂的子查询并提高可读性
- 通用 CTE: 扁平化逻辑,将嵌套子查询拆分为线性的临时表
WITH RECURSIVE: PostgreSQL 特色,用于处理层级数据(如组织架构、树形菜单)
语法:
1 | |
示例:
1 | |
DCL 数据控制语言
DCL 用于授予或撤销用户对数据库对象的访问权限
GRANT
授予用户或角色权限
语法:
1 | |
示例:
1 | |
REVOKE
撤销已授予的权限
语法:
1 | |
示例:
1 | |
Advanced SQL
Views
视图 (View) 是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图不占用物理存储空间来存储数据(除非是物化视图),数据库中只存储视图的定义
核心作用
- 简化复杂查询: 将复杂的 JOIN、聚合或子查询封装成一个简单的视图,使用者只需查询视图即可
- 安全性 (Security): 可以限制用户访问表中的特定列或行。例如,只向 HR 显示员工姓名和部门,而隐藏薪资列
- 逻辑数据独立性: 当底层表结构发生变化时,可以通过修改视图定义来保持对外接口不变,从而不影响上层应用
语法
创建视图:
1 | |
修改/替换视图:
1 | |
删除视图:
1 | |
示例
假设有一个复杂的查询,用于获取每个部门的平均薪资:
1 | |
创建视图:
1 | |
查询视图:
1 | |
Materialized Views (物化视图)
普通视图是"虚"的,每次查询都会实时执行背后的 SQL。物化视图 (Materialized View) 则是将查询结果物理存储在磁盘上。
- 优点: 查询速度极快(特别是对于复杂的聚合查询),因为不需要每次都重新计算。
- 缺点: 数据不是实时的。当底层表数据更新时,物化视图需要刷新 (Refresh)。
- 适用场景: 数据仓库、报表系统等对实时性要求不高但对性能要求高的场景。
1 | |
Functions
在 PostgreSQL 中,Function (函数) 是存储在数据库服务器上的代码块。它类似于编程语言中的函数,可以封装复杂的业务逻辑(如循环、条件判断、多次查询),并减少网络交互
核心作用
- 封装逻辑: 将复杂的 SQL 操作(如转账:扣款+入账+记日志)原子化封装
- 减少网络开销: 应用层只需发送函数名和参数,无需发送大量 SQL 语句
- 高性能: 数据库可预编译执行计划,且逻辑就在数据旁边执行,节省传输时间
语法结构
1 | |
示例
1. 简单逻辑封装 (计算会员等级):
1 | |
2. 事务性操作 (用户注册送积分):
1 | |
Procedures
Function vs. Procedure
| 特性 | Function (函数) | Procedure (存储过程) |
|---|---|---|
| 调用方式 | SELECT func_name() (作为表达式) |
只能通过 CALL proc_name() |
| 返回值 | 必须有返回值 (可以是 VOID) | 无返回值 (可通过 INOUT 参数传出) |
| 事务控制 | 不支持 (不能在内部 COMMIT/ROLLBACK) | 支持 (可以在内部进行分段提交 COMMIT) |
语法
1 | |
示例
Procedure 最大的优势是处理超长任务。例如清理 100 万条日志,如果用 Function,必须一次性做完,容易锁表或超时;用 Procedure 可以每删 1000 条就 COMMIT 一次
1 | |
Triggers
触发器 (Trigger) 是一种特殊的存储过程,它不能被显式调用,而是由数据库在特定事件(如
INSERT,UPDATE,DELETE)发生时自动执行
核心要素
- Event (事件): 触发执行的操作,如
INSERT,UPDATE,DELETE,TRUNCATE - Timing (时机):
BEFORE: 在数据修改之前执行(常用于数据校验、自动填充默认值)AFTER: 在数据修改之后执行(常用于记录审计日志、级联更新其他表)INSTEAD OF: 代替原始操作执行(通常用于视图)
- Level (级别):
FOR EACH ROW: 对受影响的每一行都执行一次(例如 UPDATE 10 行,就触发 10 次)。可以使用NEW和OLD变量引用新旧数据FOR EACH STATEMENT: 无论影响多少行,整个 SQL 语句只触发一次
创建流程 (PostgreSQL)
在 PostgreSQL 中,创建触发器通常分为两步:
- 创建一个触发器函数 (Trigger Function),返回类型必须是
TRIGGER - 创建触发器 (Trigger) 本身,将其绑定到具体的表和事件上
示例:自动更新 updated_at 时间戳
1. 创建触发器函数:
1 | |
2. 创建触发器:
1 | |
示例:审计日志 (Audit Log)
记录谁在什么时候删除了哪位员工
1. 创建审计表:
1 | |
2. 创建触发器函数:
1 | |
3. 创建触发器:
1 | |
特殊变量 (NEW vs OLD)
| 变量 | 描述 | 适用事件 |
|---|---|---|
NEW |
包含新的一行数据 | INSERT, UPDATE |
OLD |
包含旧的一行数据 | UPDATE, DELETE |
TG_OP |
触发操作的名称 (‘INSERT’, ‘UPDATE’…) | 所有 |
Normalization
数据库规范化 (Normalization) 是用来组织数据库中的数据,以减少数据冗余和提高数据完整性。通常分为不同的范式 (Normal Forms),从 1NF 到 BCNF 逐级严格
Basic Concepts: Keys (键的概念)
在讨论范式之前,必须先理清各种“键”的定义
-
Super Key (超键):
- 定义: 一个或多个属性的集合,能够唯一标识表中的每一行。
- 特点: 可能包含多余的属性。
- 示例: 在学生表中,
{Student_ID}是超键,{Student_ID, Name}也是超键。
-
Candidate Key (候选键):
- 定义: 最小的超键。即没有多余属性的超键。
- 特点: 一个表可以有多个候选键。
- 示例: 如果
Student_ID和Email都能唯一标识学生,那么它们都是候选键。
-
Primary Key (主键):
- 定义: 数据库设计者从候选键中选出的一个,作为表的主要标识符。
- 特点: 不能为 NULL,且必须唯一。通常选择短小、数值型的列。
-
Foreign Key (外键):
- 定义: 一个表中的属性,它引用另一个表的主键。
- 作用: 建立表与表之间的联系,保证引用完整性。
1NF (第一范式)
核心要求: 强调属性的原子性,即表中的每一列都是不可分割的基本数据项
- 要求:
- 表中的每一行必须是唯一的(主键)
- 表中的每一列必须包含原子的值,不能包含集合、数组或重复的组
违反 1NF 的示例:
| ID | Name | Phone_Numbers |
|---|---|---|
| 1 | Alice | 123-4567, 987-6543 |
| 2 | Bob | 555-1234 |
修正后的 1NF:
| ID | Name | Phone_Number |
|---|---|---|
| 1 | Alice | 123-4567 |
| 1 | Alice | 987-6543 |
| 2 | Bob | 555-1234 |
2NF (第二范式)
核心要求: 在满足 1NF 的基础上,消除非主属性对主键的部分函数依赖。即:所有非主属性必须完全依赖于主键
- 适用场景: 当主键由多个列组成(复合主键)时,才可能违反 2NF。如果主键只有一列,自然满足 2NF
- 问题: 如果一个非主属性只依赖于复合主键中的某一部分,就会导致数据冗余
违反 2NF 的示例:
假设主键是 (Student_ID, Course_ID)
| Student_ID | Course_ID | Student_Name | Grade |
|---|---|---|---|
| 1 | 101 | Alice | A |
| 1 | 102 | Alice | B |
Student_Name依赖于Student_ID,而不依赖于Course_ID。这就是部分依赖
修正后的 2NF (拆表):
Student 表:
| Student_ID | Student_Name |
|---|---|
| 1 | Alice |
Grade 表:
| Student_ID | Course_ID | Grade |
|---|---|---|
| 1 | 101 | A |
| 1 | 102 | B |
3NF (第三范式)
核心要求: 在满足 2NF 的基础上,消除非主属性对主键的传递函数依赖。即:非主属性必须直接依赖于主键,而不能通过其他非主属性间接依赖
- 规则: 任何非主属性都不能依赖于其他非主属性 (Attributes depend only on the Key, the whole Key, and nothing but the Key)
违反 3NF 的示例:
主键是 Employee_ID
| Employee_ID | Department_Name | Manager_Name |
|---|---|---|
| 1 | Sales | John |
| 2 | Sales | John |
Manager_Name依赖于Department_Name,而Department_Name依赖于Employee_ID- 存在传递依赖:
Employee_ID->Department_Name->Manager_Name
修正后的 3NF (拆表):
Employee 表:
| Employee_ID | Department_Name |
|---|---|
| 1 | Sales |
| 2 | Sales |
Department 表:
| Department_Name | Manager_Name |
|---|---|
| Sales | John |
BCNF (Boyce-Codd Normal Form)
核心要求: BCNF 是 3NF 的加强版,通常称为 “3.5NF”。它解决了 3NF 中主属性对非主键的依赖问题。
- 定义: 对于关系模式中的每一个函数依赖 ( 不是 的子集), 必须是超键 (Super Key)。
- 简而言之: 表中的每一个决定因素 (Determinant) 都必须是候选键。
违反 BCNF 的示例:
假设一个仓库管理表,规则是:
- 一个仓库管理员 (Keeper) 只管理一个仓库 (Warehouse)。
- 一个仓库可能有多个管理员。
- 每种物品 (Item) 在每个仓库里只存放一次。
候选键: (Warehouse, Item) 或 (Keeper, Item)。
| Warehouse | Keeper | Item |
|---|---|---|
| A | John | Table |
| A | Mike | Chair |
| B | Tom | Table |
- 存在函数依赖:
Keeper->Warehouse(因为每个管理员只在一个仓库)。 - 但是
Keeper不是候选键 (因为Keeper决定不了Item)。 - 这里
Keeper是决定因素,但不是超键,所以违反 BCNF。
修正后的 BCNF:
Keeper_Assignment 表:
| Keeper | Warehouse |
|---|---|
| John | A |
| Mike | A |
| Tom | B |
Stock 表:
| Keeper | Item |
|---|---|
| John | Table |
| Mike | Chair |
| Tom | Table |
Functional Dependencies & Algorithms
在进行数据库规范化时,我们需要一些算法工具来形式化地分析和分解关系模式
1. 属性集闭包 (Closure of Attribute Sets)
属性集闭包用于回答:“给定一组属性,能推导出哪些其他属性?”
- 符号: 表示属性集 的闭包
- 输入: 属性集 ,函数依赖集
- 算法:
- 初始化结果集
- 循环遍历 中的每一个依赖 :
- 如果 ,则将 加入 ()
- 重复步骤 2,直到 不再变化
- 用途:
- 判断超键 (Super Key): 如果 包含了表中的所有属性,则 是超键
- 验证函数依赖: 要验证 是否成立,只需检查 是否在 中
示例:
关系模式 ,函数依赖集
求 :
- 初始化:
- 使用 : ,加入 ,Result =
- 使用 : ,加入 ,Result =
- 再无变化。
结论: 。因为 ,所以 不是超键
2. 正则覆盖 (Canonical Cover)
正则覆盖 是函数依赖集 的最简形式。它去除了 中的冗余依赖,但与 逻辑等价(闭包相同)
-
目标:
- 右侧单属性: 所有的依赖右边只有一个属性 (如 拆解为 )
- 无冗余依赖: 去掉某个依赖后,闭包不变。
- 无冗余属性: 去掉某个依赖左边的属性后,闭包不变 (如 ,如果 已存在,则 冗余)
-
算法步骤:
- 单属性化: 利用合并规则将所有依赖的右边拆解为单个属性
- 消除左侧冗余属性: 对于 ,检查 中的属性是否多余
- 如果 中有个属性 ,且 $(X-{A})^+ $ 包含 ,则 是多余的
- 消除冗余依赖: 对于每一个依赖 ,检查它是否多余
- 计算
- 如果在 下, 仍然包含 ,说明该依赖可以被其他依赖推导出来,删除它
- 合并: 将左侧相同的依赖合并 (如 合并为 )
示例:
- 单属性化: 已经是单属性
- 左侧冗余: 无复合属性,跳过
- 冗余依赖:
- 检查 :
- 暂时去掉它,剩余
- 在 中计算 : ,所以
- 在 中,说明 是冗余的。删除。
- 结果: 。
E-R Diagram Design
Chen’s Notation (陈氏表示法)
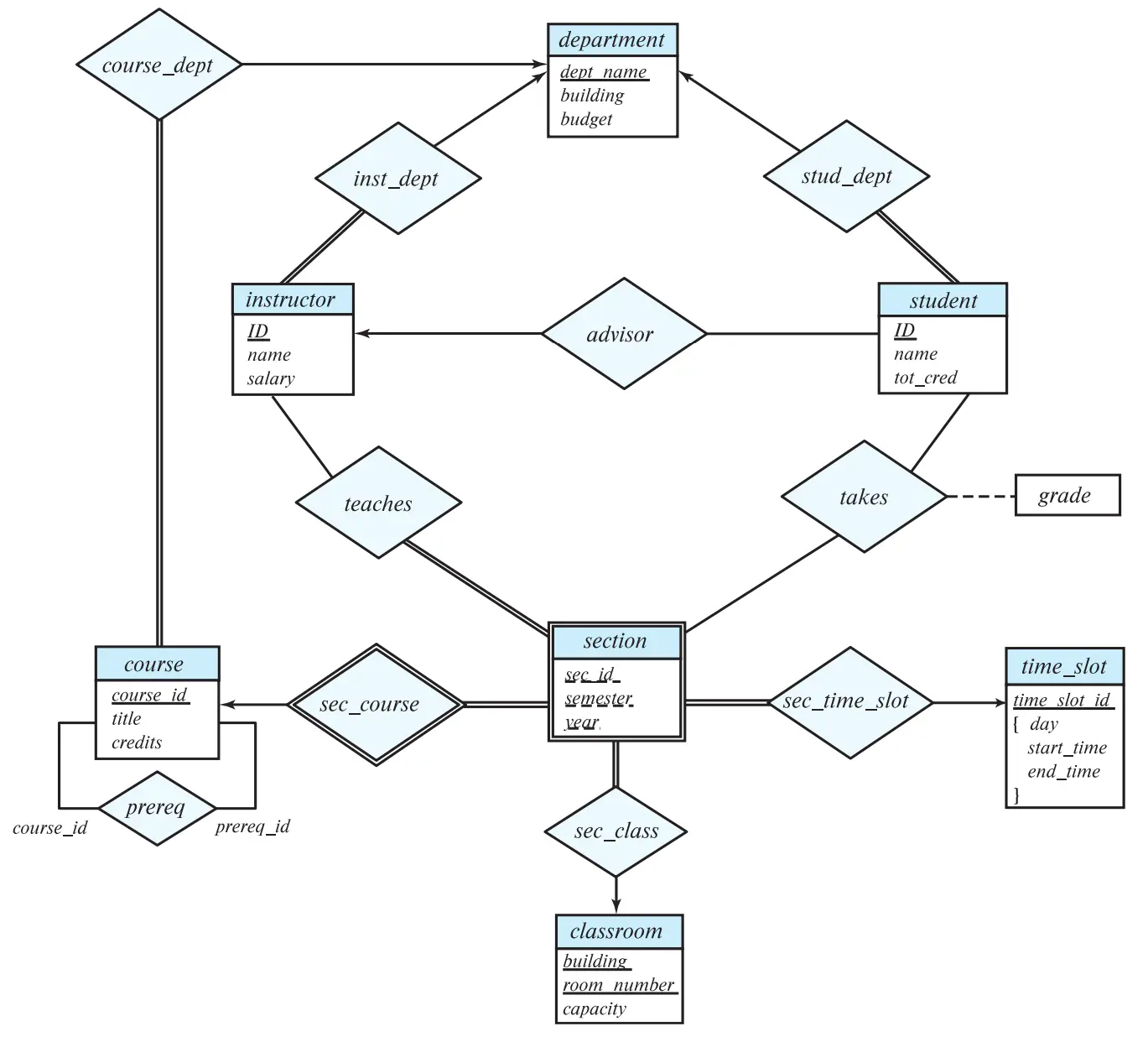
1. 基本组件 (Basic Components)
| 组件 (Component) | 符号 (Symbol) | 描述 |
|---|---|---|
| Entity (实体) | 矩形 (Rectangle) | 现实世界中可区分的对象。例如:Student, Car |
| Attribute (属性) | 椭圆 (Ellipse) | 描述实体的特征。实体与属性用直线连接。例如:Name, Age |
| Relationship (关系) | 菱形 (Diamond) | 实体之间的关联。用直线连接相关的实体。例如:Enrolls, Works_For |
2. 属性类型 (Attribute Types)
-
Key Attribute (主键属性):
- 符号: 椭圆内文字带下划线
- 含义: 唯一标识实体的属性。例如:
Student_ID
-
Multivalued Attribute (多值属性):
- 符号: 双边椭圆 (Double Ellipse)
- 含义: 一个实体在该属性上可能有多个值。例如:
Phone_Numbers(一个人可能有多个电话)
-
Derived Attribute (派生属性):
- 符号: 虚线椭圆 (Dashed Ellipse)
- 含义: 该属性的值不是直接存储的,而是从其他属性计算得来的。例如:
Age(可以从Birth_Date计算得出)
-
Composite Attribute (复合属性):
- 符号: 属性延伸出其他属性
- 含义: 属性可以被细分为更小的部分。例如:
Name可以分为First_Name和Last_Name
3. 弱实体与强实体 (Weak & Strong Entities)
-
Weak Entity (弱实体):
- 符号: 双边矩形 (Double Rectangle)
- 含义: 没有自己的主键,必须依赖于强实体 (Owner Entity) 才能被唯一标识的实体。例如:
Dependent(家属) 依赖于Employee - Partial Key (部分键): 弱实体的区分符,用虚下划线表示
-
Identifying Relationship (识别关系):
- 符号: 双边菱形 (Double Diamond)
- 含义: 连接弱实体及其所有者强实体的关系
4. 约束 (Constraints)
基数比率 (Cardinality Ratios):
描述一个实体通过关系可以关联多少个其他实体,标注在关系连线上
- 1:1 (One-to-One): 关系两边分别标
1。例如:Manager--1--<Manages>--1--Department - 1:N (One-to-Many): 一边标
1,另一边标N,箭头多指向1。例如:Department<–1--<Has>--N--Employee - M:N (Many-to-Many): 一边标
M,另一边标N。例如:Student--M--<Enrolls>--N--Course
参与约束 (Participation Constraints):
描述实体是否存在依赖于关系
-
Total Participation (全部参与 / 强制参与):
- 符号: 双线 (Double Line) 连接实体与关系
- 含义: 实体集中的每个实体都必须参与该关系。例如:每个
Loan(贷款) 必须属于某个Branch(支行)
-
Partial Participation (部分参与):
- 符号: 单线 (Single Line) 连接
- 含义: 实体集中只有部分实体参与该关系。例如:并非每个
Employee都Manages(管理) 一个部门
Transactions
事务 (Transaction) 是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。事务的主要目的是为了保证数据的一致性和完整性。
1. ACID 特性
一个标准的数据库事务必须满足 ACID 四大特性:
- Atomicity (原子性):
- 事务中的所有操作要么全部完成,要么全部不完成。
- 如果事务在执行过程中发生错误,会被回滚 (Rollback) 到事务开始前的状态,就像这个事务从未执行过一样。
- Consistency (一致性):
- 事务执行前后,数据库必须始终保持一致性状态。
- 数据必须满足所有定义的规则(如外键约束、CHECK 约束等)。
- Isolation (隔离性):
- 多个并发事务之间是相互隔离的,一个事务的执行不应影响其他事务。
- 具体的隔离程度取决于隔离级别。
- Durability (持久性):
- 一旦事务提交 (Commit),其对数据的修改就是永久的,即使系统崩溃也不会丢失。
2. 事务控制语句 (TCL)
BEGIN或START TRANSACTION: 显式开启一个事务。COMMIT: 提交事务,保存更改。ROLLBACK: 回滚事务,撤销未提交的更改。SAVEPOINT name: 在事务中创建一个保存点。ROLLBACK TO name: 回滚到指定的保存点,而不是回滚整个事务。
示例:
1 | |
3. 并发问题 (Concurrency Issues)
当多个事务并发运行时,可能会出现以下问题:
- Dirty Read (脏读): 事务 A 读取了事务 B 未提交的数据。如果事务 B 后来回滚了,事务 A 读到的就是无效数据。
- Non-repeatable Read (不可重复读): 事务 A 在同一个事务中读取了同一行两次,但得到的结果不同。这是因为在两次读取之间,事务 B 修改或删除了该行并提交了。
- Phantom Read (幻读): 事务 A 在同一个事务中按相同条件查询了两次,但第二次查询出的行数不同。这是因为在两次查询之间,事务 B 插入了新行并提交了。
4. 隔离级别 (Isolation Levels)
SQL 标准定义了四种隔离级别,用于平衡并发性能和数据安全性(级别由低到高):
| 隔离级别 (Isolation Level) | 脏读 (Dirty Read) | 不可重复读 (Non-repeatable) | 幻读 (Phantom Read) | 性能 |
|---|---|---|---|---|
| Read Uncommitted (读未提交) | 可能 | 可能 | 可能 | 最高 |
| Read Committed (读已提交) | 不可能 | 可能 | 可能 | 高 (PostgreSQL 默认) |
| Repeatable Read (可重复读) | 不可能 | 不可能 | 可能 | 中 (MySQL InnoDB 默认) |
| Serializable (串行化) | 不可能 | 不可能 | 不可能 | 最低 (最安全) |
- Read Committed: 只能读到其他事务已经提交的数据。解决了脏读。
- Repeatable Read: 保证在同一个事务中多次读取同一数据结果是一致的。解决了脏读和不可重复读。
- Serializable: 强制事务串行执行。解决了所有并发问题,但并发性能极差,容易导致锁竞争。
核心实现机制:MVCC (多版本并发控制)
大多数现代数据库(如 PostgreSQL, MySQL InnoDB)使用 MVCC (Multi-Version Concurrency Control) 来实现 Read Committed 和 Repeatable Read,而不是单纯依赖锁(锁会阻塞读操作)。
-
基本原理:
- 数据库为每一行数据维护多个版本(通过 undo log 或 hidden columns)。
- 读操作不阻塞写操作,写操作也不阻塞读操作。
-
Read Committed 的实现:
- Read View (快照) 生成时机: 在事务中,每次执行 SELECT 语句时都会生成一个新的 Read View。
- 效果: 如果在两次查询之间,有其他事务提交了修改,生成的快照就会不同,因此能读到最新的已提交数据(导致不可重复读)。
-
Repeatable Read 的实现:
- Read View (快照) 生成时机: 在事务中,第一次执行 SELECT 语句时生成一个 Read View,并在整个事务期间复用这个快照。
- 效果: 无论其他事务是否提交修改,当前事务看到的始终是第一次查询时的数据状态,从而保证了可重复读。
设置隔离级别:
1 | |
5. Locks (锁)
锁 (Lock) 是数据库系统用来管理并发访问的一种机制,用于确保数据的一致性和完整性
锁的类型 (Types of Locks)
- Shared Lock (S-Lock / 共享锁 / 读锁):
- 多个事务可以同时获取同一对象的共享锁进行读取
- 如果一个对象有共享锁,其他事务不能获取该对象的排他锁(不能修改),但可以获取共享锁(可以读取)
- Exclusive Lock (X-Lock / 排他锁 / 写锁):
- 事务为了修改数据而获取的锁
- 如果一个事务获取了对象的排他锁,其他事务不能获取该对象的任何锁(既不能读也不能写)
Relational Algebra
关系代数 (Relational Algebra) 是一种过程化查询语言。它包含一组运算,这些运算以一个或两个关系(表)作为输入,并产生一个新的关系作为输出。它是 SQL 语言的理论基础。
1. 基本运算 (Fundamental Operations)
这 6 个运算是关系代数的核心,其他运算都可以由它们组合而成。
1.1 选择 (Select, )
- 定义: 选择满足给定谓词 的行(元组)。
- 符号:
- SQL 对应:
WHERE子句 - 示例:
- 查询物理系 (Physics) 的所有教师:
- SQL:
SELECT * FROM Instructor WHERE dept_name = 'Physics';
1.2 投影 (Project, )
- 定义: 选择指定的列(属性),并自动去重。
- 符号:
- SQL 对应:
SELECT DISTINCT col1, col2(注意:关系代数默认去重,SQL 默认不去重) - 示例:
- 查询所有教师的 ID 和姓名:
- SQL:
SELECT DISTINCT ID, name FROM Instructor;
1.3 并运算 (Union, )
- 定义: 返回包含在关系 或 或两者中的所有元组。要求 和 具有相同的属性数量和兼容的属性域。
- 符号:
- SQL 对应:
UNION - 示例:
- SQL: 选出 Fall 或 Spring 学期开设的所有课程 ID。
1.4 集合差 (Set Difference, )
- 定义: 返回属于关系 但不属于关系 的元组。
- 符号:
- SQL 对应:
EXCEPT(在 Oracle 中是MINUS) - 示例:
- SQL: 选出在 Fall 学期开设但不在 Spring 学期开设的课程。
1.5 笛卡尔积 (Cartesian Product, )
- 定义: 将关系 中的每一行与关系 中的每一行进行拼接。
- 符号:
- SQL 对应:
CROSS JOIN或FROM table1, table2 - 示例:
- 结果包含所有可能的 (教师, 授课) 组合。通常本身没有意义,需要配合选择运算使用。
1.6 更名运算 (Rename, )
- 定义: 为关系或属性重新命名。
- 符号: (将表达式 E 的结果重命名为 X)
- SQL 对应:
AS - 示例:
- SQL:
SELECT * FROM Employee AS Emp;
2. 扩展运算 (Additional Operations)
为了方便使用,基于基本运算定义了一些常用的扩展运算。
2.1 集合交 (Set Intersection, )
- 定义: 返回同时属于关系 和 的元组。
- 推导:
- SQL 对应:
INTERSECT
2.2 自然连接 (Natural Join, )
- 定义: 基于两个关系中名称相同的所有属性进行的等值连接,并去除重复列。
- 符号:
- 推导:
- SQL 对应:
NATURAL JOIN - 示例:
- 自动匹配两个表中的
ID列相等的情况。
2.3 连接 (Theta Join, )
- 定义: 笛卡尔积后进行选择运算。
- 符号:
- SQL 对应:
JOIN ON或WHERE - 示例:
2.4 赋值 (Assignment, )
- 定义: 将右侧表达式的结果赋给左侧的临时关系变量。
- 符号:
- 用途: 将复杂的查询拆分为多个步骤。
Indexing
索引 (Index) 是数据库中用于提高数据检索速度的数据结构。它类似于书籍的目录,允许数据库快速找到特定的行,而无需扫描整个表。
1. 基础知识
- 优点:
- 极大地加快查询速度(SELECT, WHERE, JOIN)。
- 可以强制实施唯一性约束 (UNIQUE Index)。
- 缺点:
- 占用额外的存储空间。
- 降低写操作的速度 (INSERT, UPDATE, DELETE),因为每次修改数据时,索引也需要更新。
2. 语法
1 | |
3. 常见索引类型
- B-Tree 索引 (默认): 最常用的索引,支持全键值、键值范围和键前缀查找。
- Hash 索引: 基于哈希表实现,只有精确匹配索引所有列的查询才有效(仅支持
=和IN)。不支持范围查询。 - Bitmap 索引 (位图索引): 适用于列的基数 (Cardinality) 很低的情况(如性别、省份)。在数据仓库中常用。
- Clustered Index (聚簇索引):
- 数据的物理存储顺序与索引顺序一致。
- 一张表只能有一个聚簇索引(通常是主键)
- Non-Clustered Index (非聚簇索引 / 二级索引):
- 索引中存储的是索引列的值和指向数据行的指针(或主键)
- 一张表可以有多个非聚簇索引。
4. B-Tree (Balanced Tree) 实现详解
B-Tree 是一种自平衡的树,设计初衷是为磁盘等直接存取辅助存储设备提供一种高效的索引结构
核心概念:阶 (Order)
B-Tree 通常被描述为 阶 (m-order) 树,这意味着:
- 每个节点最多有 个子节点。
- 每个节点最多有 个 Key。
- 除根节点外,每个节点至少有 个子节点(即半满状态)。
示例: 一个 3阶 B-Tree (Order = 3):
- 每个节点最多存 2 个 Key。
- 每个节点最多有 3 个子节点 (3路)。
3阶 B-Tree 结构示意图 (ASCII):
1 | |
查找 (Search) 示例:
假设要在上面的树中查找 25:
- 比较根节点 [30]: 25 < 30,向左子树走。
- 比较节点 [10]: 25 > 10,向右子树走(假设 10 右边的指针指向包含 20-29 的范围)。
- 到达叶子节点: 遍历节点内的 Key,找到 25,返回 Data。
插入 (Insert) 示例:分裂与上浮
场景: 基于上图的 3阶 B-Tree,我们尝试连续插入 65 和 66,演示从叶子节点到根节点的级联分裂过程。
Step 1: 插入 65 (节点变满)
- 查找发现应插入叶子节点
[60]。 - 插入后该节点变为
[ 60 | 65 ]。 - Key 数量 (2) 达到上限 (Max Keys),但未溢出,插入成功。
1 | |
Step 2: 插入 66 (叶子节点分裂 -> 父节点溢出)
- 插入后叶子节点临时变为
[ 60 | 65 | 66 ](溢出)。 - 分裂: 中间值 65 上浮。原节点分裂为
[60]和[66]。 - 65 进入父节点
[ 50 | 70 ],父节点临时变为[ 50 | 65 | 70 ](溢出)。
1 | |
Step 3: 父节点分裂 (级联分裂 -> 根节点更新)
- 父节点溢出,中间值 65 继续上浮。
- 原父节点分裂为
[50]和[70]。 - 65 进入根节点
[ 30 ],根节点变为[ 30 | 65 ](未溢出)。
1 | |
搜索效率:
- 时间复杂度: 。
- 特点: 搜索可能在非叶子节点提前结束(如果正好匹配到当前节点的 Key),而 B+ Tree 必须搜索到叶子节点。
为什么数据库更倾向于 B+ Tree (补充背景):
虽然 B-Tree 很优秀,但 B+ Tree 在内部节点不存 Data,因此相同大小的磁盘页可以存储更多 Key,扇出 (Fan-out) 更大,树更矮;且 B+ Tree 叶子节点有链表连接,更适合范围扫描