部分笔记摘录自hello-algo
栈 & 队列
双向队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 class ArrayDeque {private int [] nums; private int front; private int queSize; public ArrayDeque (int capacity) {this .nums = new int [capacity];0 ;public int capacity () {return nums.length;public int size () {return queSize;public boolean isEmpty () {return queSize == 0 ;private int index (int i) {return (i + capacity()) % capacity();public void pushFirst (int num) {if (queSize == capacity()) {"双向队列已满" );return ;1 );public void pushLast (int num) {if (queSize == capacity()) {"双向队列已满" );return ;int rear = index(front + queSize);public int popFirst () {int num = peekFirst();1 );return num;public int popLast () {int num = peekLast();return num;public int peekFirst () {if (isEmpty())throw new IndexOutOfBoundsException ();return nums[front];public int peekLast () {if (isEmpty())throw new IndexOutOfBoundsException ();int last = index(front + queSize - 1 );return nums[last];public int [] toArray() {int [] res = new int [queSize];for (int i = 0 , j = front; i < queSize; i++, j++) {return res;
树
二叉树
1 2 3 4 5 6 7 class TreeNode {int val; int x) { val = x; }
层序遍历(BFS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 levelOrder (TreeNode root) {new LinkedList <>();new ArrayList <>();while (!queue.isEmpty()) {TreeNode node = queue.poll(); if (node.left != null )if (node.right != null )return list;
前序/中序/后续遍历(DFS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void preOrder (TreeNode root) {if (root == null )return ;void inOrder (TreeNode root) {if (root == null )return ;void postOrder (TreeNode root) {if (root == null )return ;
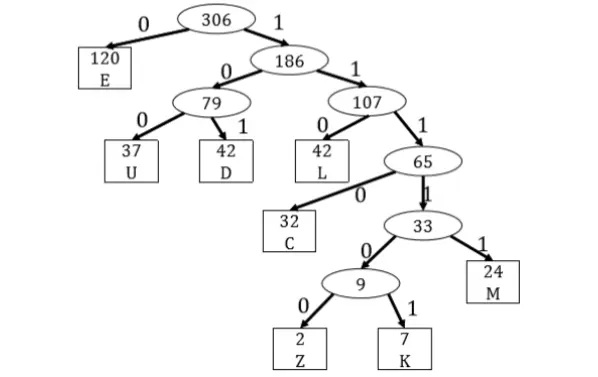
哈夫曼编码
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 函数 HuffmanCoding(字符集 C) :|C | Q = 优先队列(按频率升序) # 1. 初始化队列 对于 C 中的每个字符 c: 创建一个节点 z z.字符 = c z.频率 = c.频率 Insert(Q, z ) # 2. 构建哈夫曼树 当 Q .size > 1 时执行: # 取出两个最小的 x = ExtractMin(Q) y = ExtractMin(Q) # 合并为一个新节点 z = 新节点() z.left = x z.right = y z.频率 = x.频率 + y.频率 # 将新节点放回队列 Insert(Q, z ) # 3. 返回根节点 Return ExtractMin(Q) 函数 GenerateCodes(节点 node , 当前编码 code ) : 如果 node 是叶子节点: 打印/ 存储 node.字符 : code 返回 GenerateCodes(node .left , code + "0" ) GenerateCodes(node .right , code + "1" )
BST
https://www.hello-algo.com/chapter_tree/binary_search_tree/
前序查找
时间复杂度 O(h)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public long predecessorQuery (Node root, long q) {if (root == null ) {return -1 ;else if (root.element == q) {return root.element;else if (root.element > q) {return predecessorQuery(root.leftChild, q);else {long temp = predecessorQuery(root.rightChild, q);if (temp == -1 ) {return root.element;else {return temp;
后序查找
时间复杂度 O(h)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public long successorQuery (Node root, long q) {if (root == null ) {return -1 ;else if (root.element == q) {return root.element;else if (root.element > q) {long temp = successorQuery(root.leftChild, q);if (temp == -1 ) {return root.element;else {return temp;else {return successorQuery(root.rightChild, q);
AVL
https://www.hello-algo.com/chapter_tree/avl_tree/
策略表:
失衡节点的平衡因子
子节点的平衡因子
应采用的旋转方法
> 1 > 1 > 1 ≥ 0 \geq 0 ≥ 0 右旋
> 1 > 1 > 1 < 0 <0 < 0 先左旋后右旋
< − 1 < -1 < − 1 ≤ 0 \leq 0 ≤ 0 左旋
< − 1 < -1 < − 1 > 0 >0 > 0 先右旋后左旋
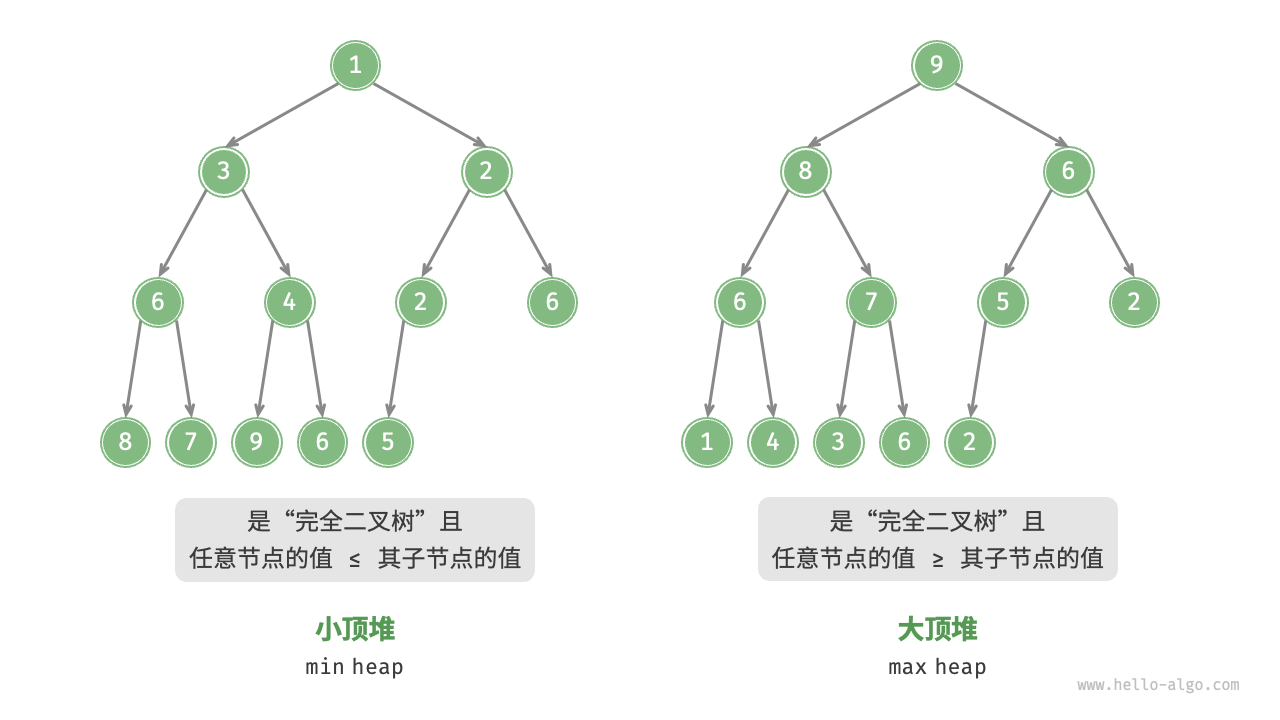
堆
堆(heap)是一种满足特定条件的完全二叉树,主要可分为两种类型,如下图所示。
小顶堆(min heap) :任意节点的值 ≤ \leq ≤ 大顶堆(max heap) :任意节点的值 ≥ \geq ≥
下文实现的是大顶堆,若要将其转换为小顶堆,只需将所有大小逻辑判断进行逆转(例如,将 ≥ \geq ≥ ≤ \leq ≤
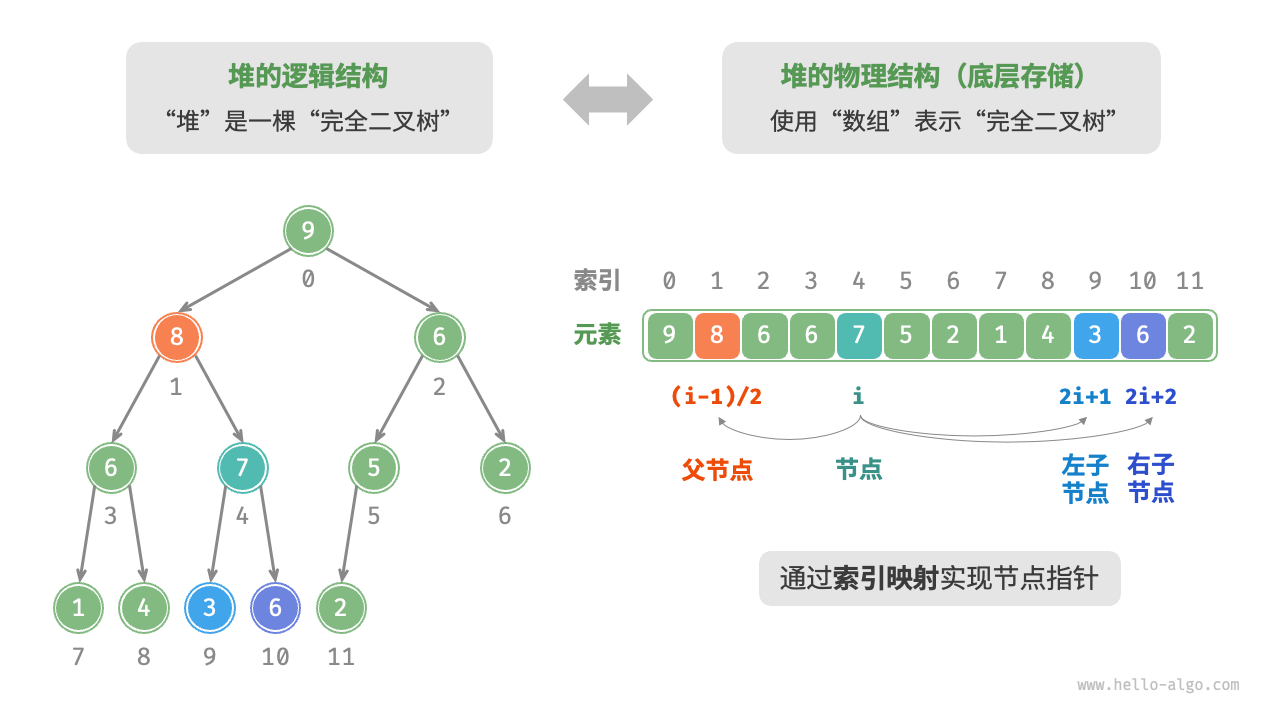
堆的存储与表示
“二叉树”章节讲过,完全二叉树非常适合用数组来表示。由于堆正是一种完全二叉树,因此我们将采用数组来存储堆 。
当使用数组表示二叉树时,元素代表节点值,索引代表节点在二叉树中的位置。节点指针通过索引映射公式来实现 。
如下图所示,给定索引 i i i 2 i + 1 2i + 1 2 i + 1 2 i + 2 2i + 2 2 i + 2 ( i − 1 ) / 2 (i - 1) / 2 ( i − 1 ) /2
堆的操作
元素入堆
时间复杂度为 O ( log n ) O(\log n) O ( log n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void push (int val) {1 );void siftUp (int i) {while (true ) {int p = parent(i);if (p < 0 || maxHeap.get(i) <= maxHeap.get(p))break ;
元素出堆
时间复杂度为 O ( log n ) O(\log n) O ( log n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int pop () {if (isEmpty())throw new IndexOutOfBoundsException ();0 , size() - 1 );int val = maxHeap.remove(size() - 1 );0 );return val;void siftDown (int i) {while (true ) {int l = left(i), r = right(i), ma = i;if (l < size() && maxHeap.get(l) > maxHeap.get(ma))if (r < size() && maxHeap.get(r) > maxHeap.get(ma))if (ma == i)break ;
Root-fix 建堆
时间复杂度为 O ( n ) O(n) O ( n )
证明如下:
假设树的高度为 h h h log N \log N log N S S S
倒数第 1 层(叶子):2 h 2^h 2 h 2 h − 1 2^{h-1} 2 h − 1
倒数第 3 层:2 h − 2 2^{h-2} 2 h − 2
…
根节点:2 0 2^0 2 0 h h h
总工作量公式:
S = ∑ i = 0 h 2 i ⋅ ( h − i ) = 2 0 ⋅ h + 2 1 ⋅ ( h − 1 ) + ⋯ + 2 h − 1 ⋅ 1 S = \sum_{i=0}^{h} 2^i \cdot (h-i) = 2^0 \cdot h + 2^1 \cdot (h-1) + \dots + 2^{h-1} \cdot 1
S = i = 0 ∑ h 2 i ⋅ ( h − i ) = 2 0 ⋅ h + 2 1 ⋅ ( h − 1 ) + ⋯ + 2 h − 1 ⋅ 1
利用错位相减法求和,结果为:
S = 2 h + 1 − h − 2 S = 2^{h+1} - h - 2
S = 2 h + 1 − h − 2
因为 N ≈ 2 h + 1 N \approx 2^{h+1} N ≈ 2 h + 1
S ≈ N − log N − 2 S \approx N - \log N - 2
S ≈ N − log N − 2
结论:
S = O ( N ) S = O(N)
S = O ( N )
1 2 3 4 5 6 7 8 MaxHeap(List<Integer> nums) {new ArrayList <>(nums);for (int i = parent(size() - 1 ); i >= 0 ; i--) {
图
图(graph) 是一种非线性数据结构,由 顶点(vertex) 和 边(edge) 组成。我们可以将图 G G G V V V E E E
V = { 1 , 2 , 3 , 4 , 5 } E = { ( 1 , 2 ) , ( 1 , 3 ) , ( 1 , 5 ) , ( 2 , 3 ) , ( 2 , 4 ) , ( 2 , 5 ) , ( 4 , 5 ) } G = { V , E } \begin{aligned}
V & = \{ 1, 2, 3, 4, 5 \} \newline
E & = \{ (1,2), (1,3), (1,5), (2,3), (2,4), (2,5), (4,5) \} \newline
G & = \{ V, E \} \newline
\end{aligned}
V E G = { 1 , 2 , 3 , 4 , 5 } = {( 1 , 2 ) , ( 1 , 3 ) , ( 1 , 5 ) , ( 2 , 3 ) , ( 2 , 4 ) , ( 2 , 5 ) , ( 4 , 5 )} = { V , E }
常见术语
有向图:directed graph,Uni directional
无向图:Un directed Graph,Bi directional
连通图(connected graph):从某个顶点出发,可以到达其余任意顶点
非连通图(disconnected graph):从某个顶点出发,至少有一个顶点无法到达
邻接(adjacency):当两顶点之间存在边相连时
路径(path):从顶点 A 到顶点 B 经过的边构成的序列被称为从 A 到 B 的“路径”
度(degree):一个顶点拥有的边数。对于有向图,入度(in-degree) 表示有多少条边指向该顶点,出度(out-degree) 表示有多少条边从该顶点指出
图的表示
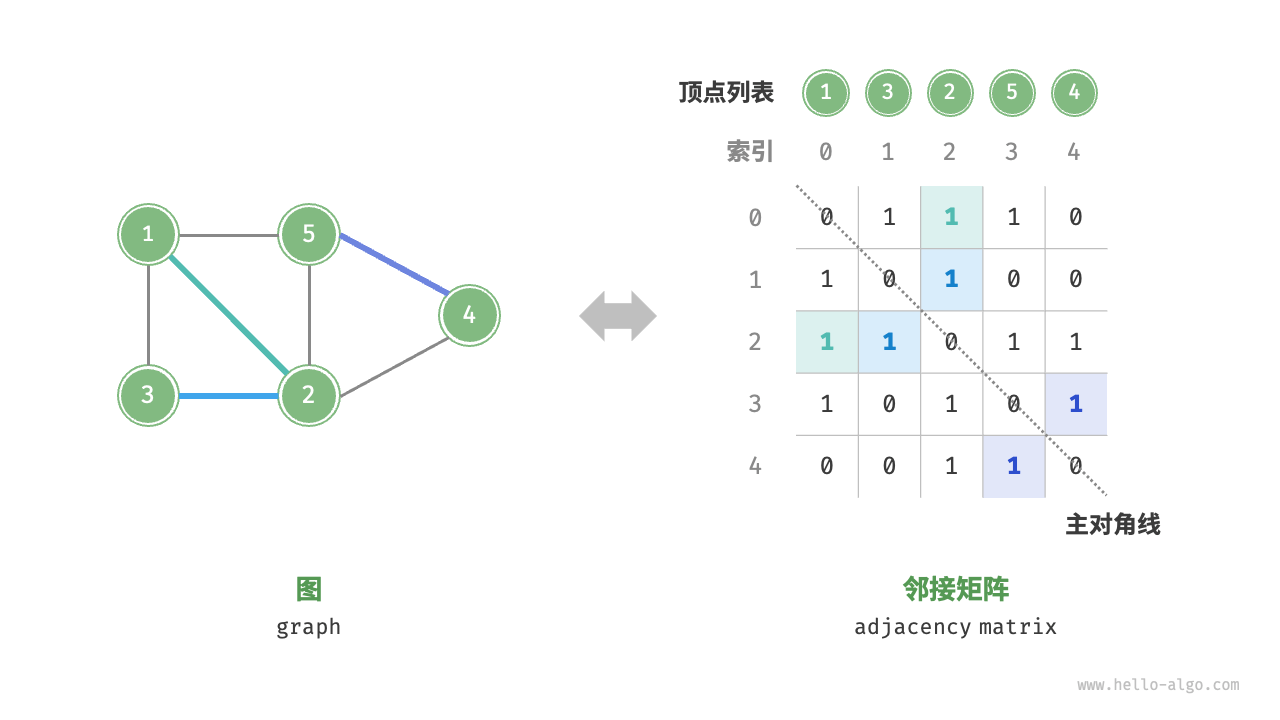
邻接矩阵
设图的顶点数量为 n n n 邻接矩阵(adjacency matrix) 使用一个 n × n n \times n n × n 1 1 1 0 0 0
如下图所示,设邻接矩阵为 M M M V V V M [ i , j ] = 1 M[i, j] = 1 M [ i , j ] = 1 V [ i ] V[i] V [ i ] V [ j ] V[j] V [ j ] M [ i , j ] = 0 M[i, j] = 0 M [ i , j ] = 0
对于无向图,两个方向的边等价,此时邻接矩阵关于主对角线对称
将邻接矩阵的元素从 1 1 1 0 0 0
S p a c e = O ( ∣ V ∣ 2 ) Space = O(|V|^2) Sp a ce = O ( ∣ V ∣ 2 )
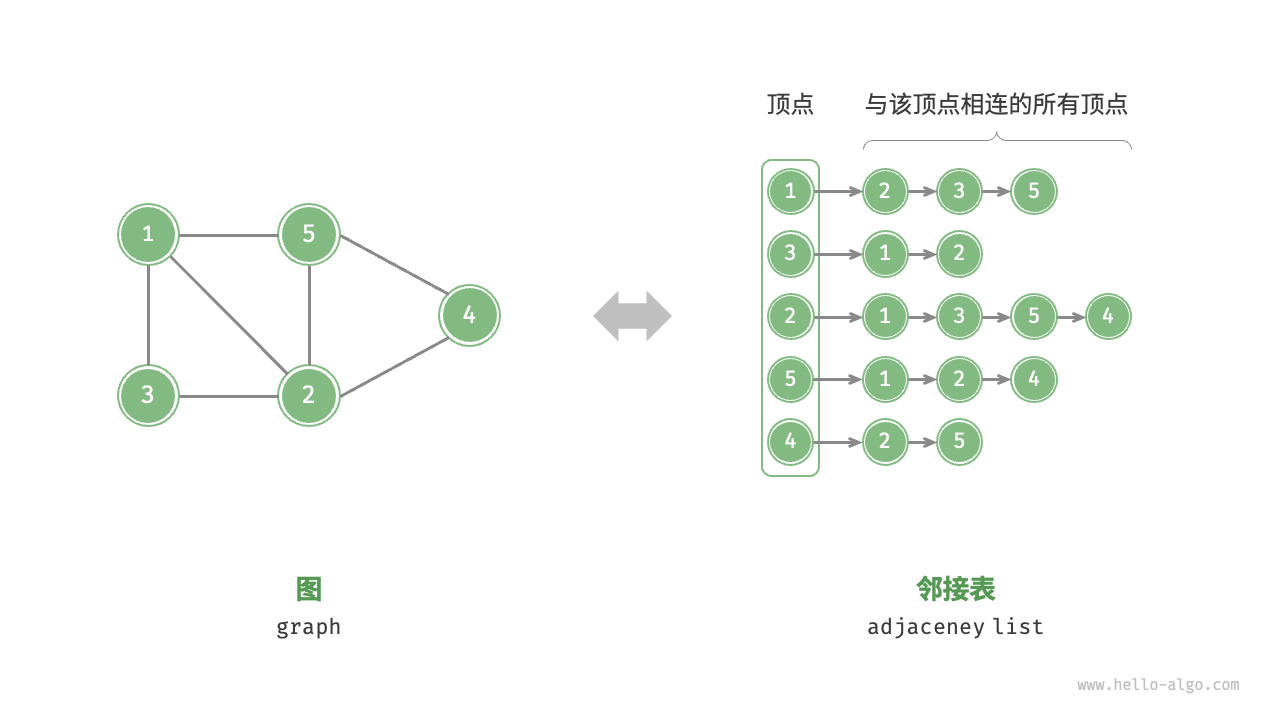
邻接表
邻接表(adjacency list) 使用 n n n i i i i i i
邻接表仅存储实际存在的边,而边的总数通常远小于 n 2 n^2 n 2 S p a c e = O ( ∣ V ∣ + ∣ E ∣ ) Space = O(|V|+|E|) Sp a ce = O ( ∣ V ∣ + ∣ E ∣ )
观察上图,邻接表结构与哈希表中的“链式地址”非常相似,因此我们也可以采用类似的方法来优化效率 。比如当链表较长时,可以将链表转化为 AVL 树或红黑树,从而将时间效率从 O ( n ) O(n) O ( n ) O ( log n ) O(\log n) O ( log n ) O ( 1 ) O(1) O ( 1 )
Java 示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import java.util.*;class Graph {int V; public Graph (int V) {this .V = V;new ArrayList [V];for (int i = 0 ; i < V; i++) {new ArrayList <>();public void addEdge (int u, int v) {
下面的Java示例沿用此代码模板
BFS 与 DFS
广度优先搜索 (BFS - Breadth-First Search)
BFS 就像是水波纹扩散 或者剥洋葱 。它从起点开始,先访问离起点最近的所有节点(第1层),然后再访问离起点稍远的所有节点(第2层),以此类推。核心数据结构 :队列 (Queue)
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 BFS(Graph, StartNode):add (StartNode)WHILE Q is not empty:PRINT CurrentNodeFOR EACH Neighbor in Graph.neighbors(CurrentNode):IF Neighbor is NOT in Visited:add (Neighbor)
Java示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static void bfs (Graph g, int startNode) {"--- BFS 开始 (起点: " + startNode + ") ---" );boolean [] visited = new boolean [g.V];new LinkedList <>(); true ;while (!queue.isEmpty()) {int curr = queue.poll();" " );for (int neighbor : g.adj[curr]) {if (!visited[neighbor]) {true ;
深度优先搜索 (DFS - Depth-First Search)
DFS 就像是走迷宫 。它选择一条路一直走到黑(直到无路可走),然后回溯 (Backtrack) 到上一个路口,选择另一条没走过的路继续尝试。核心数据结构 :栈 (Stack) (通常通过递归 的系统栈实现,也可以手动用 Stack)
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 DFS (Graph) in Graph:in Visited:DFS_Recursive (Node, Visited)DFS_Recursive (CurrentNode, Visited) .add (CurrentNode)in Graph.neighbors (CurrentNode):in Visited:DFS_Recursive (Neighbor, Visited)
Java示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private static void dfsUtil (Graph g, int v, boolean [] visited) {true ;" " );for (int neighbor : g.adj[v]) {if (!visited[neighbor]) {public static void dfs (Graph g, int startNode) {"--- DFS 开始 (起点: " + startNode + ") ---" );boolean [] visited = new boolean [g.V];
DAG 有向无环图
判断是否为DAG (Directed Acyclic Graph) 的经典方法有两种
DFS (三色标记法)
BFS (Kahn 算法 / 拓扑排序法)
DFS (三色标记法)
我们需要三个状态 来区分“正在递归栈中”和“已经搜索完毕”
三种颜色(状态):
0 (White/未访问) :还没走到这里1 (Gray/正在访问) :正在这个节点的递归栈里(我在它的子孙节点中打转,还没回溯回来)。如果碰到了状态 1 的点,说明遇到了“回头路”,即有环! 2 (Black/已完成) :这个点及其所有子孙都遍历完了,没发现环
从任意点出发 DFS,如果你走着走着,看到了一个标为 1 (Gray) 的节点,说明你回到了祖先节点 → \to →
Java示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public static boolean hasCycle (int n, ArrayList<Integer>[] adj) {int [] state = new int [n]; for (int i = 0 ; i < n; i++) {if (state[i] == 0 ) {if (dfsCheckCycle(i, adj, state)) {return true ; return false ; private static boolean dfsCheckCycle (int u, ArrayList<Integer>[] adj, int [] state) {1 ; for (int v : adj[u]) {if (state[v] == 1 ) {return true ; if (state[v] == 0 ) {if (dfsCheckCycle(v, adj, state)) {return true ;2 ; return false ;
BFS (Kahn 算法 / 拓扑排序法)
这也是拓扑排序 (Topological Sort) 的核心逻辑
核心思路: DAG 的一个重要性质是:一定存在一个“入度为 0”的点 (没有任何箭头指向它的点,即起跑线)
找到所有 入度 (Indegree) 为 0 的点,把它们“删掉”(放入队列)
当你删掉一个点时,它发出的箭头也随之消失,这可能会让它的邻居的入度变成 0
重复这个过程
结论 :如果你能删光所有点,它就是 DAG。如果最后还剩下一堆点删不掉(因为它们互指,入度永远不为 0),那就是有环
Java示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public class TopologicalSort {public static int [] getTopologicalSort(int n, ArrayList<Integer>[] adj) {int [] inDegree = new int [n];for (int u = 0 ; u < n; u++) {for (int v : adj[u]) {new LinkedList <>();for (int i = 0 ; i < n; i++) {if (inDegree[i] == 0 ) {int [] result = new int [n];int index = 0 ;while (!queue.isEmpty()) {int u = queue.poll();for (int v : adj[u]) {if (inDegree[v] == 0 ) {if (index != n) {return new int [0 ]; return result;
Dijkstra 算法
Dijkstra 算法是一种用于在正权图 中查找从单一源点 到所有其他节点 的最短路径的经典算法。它采用了贪心策略 (Greedy Strategy),并被证明具有普遍最优性
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 function Dijkstra(G, s):// 1 . 初始化 (Initialization)// 初始化距离数组为无穷大,前驱数组为 null1 到 N:// 源点到自己的距离为 0 0 // 初始化最小堆,并将源点推入// 堆中元素格式:(当前距离, 节点编号)0 , s) )// 2 . 主循环 (Processing)// 弹出堆顶元素:距离源点最近的“未知”节点// [关键优化:懒惰删除检查]// 如果从堆中弹出的距离 d 大于当前记录的最短距离 dist[u],// 说明这是一个“过时”的记录(该节点已被通过更短的路径处理过),直接跳过。continue // 3 . 遍历邻居并松弛 (Traverse Neighbors & Relax)// 遍历 u 的所有出边 (u -> v),权重为 win G[u]:// 计算经由 u 到达 v 的新距离// [松弛操作]// 如果找到更短的路径// 更新最短距离// 记录前驱节点(用于回溯路径)// 将更新后的距离和节点推入堆中// 注意:旧的 (old_dist, v) 仍然在堆中,但在弹出时会被上方的“懒惰删除检查”过滤掉
Bellman-Ford 算法
Bellman-Ford (贝尔曼-福特) 也是一种用于在加权图中寻找单源最短路径 (Single-Source Shortest Path) 的经典算法,它不贪心但是可以处理负权图
Bellman-Ford 需要进行 V-1 轮松弛,每一轮松弛都要遍历所有边
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 function BellmanFord(G, s):// 1 . 初始化 (Initialization)// 初始化距离数组为无穷大,前驱数组为 null1 到 N:// 源点到自己的距离为 0 0 // 获取图中所有的边列表 (Edge List)// 形式为:(u, v, w) 表示从 u 到 v 权重为 w// 2 . 连续松弛 N-1 轮 (Relaxation Phase)// 在没有任何负权环的图中,任意最短路径最多包含 N-1 条边。// 所以我们需要对所有边进行 N-1 轮松弛操作。1 次:// 遍历图中的每一条边 (u, v, w)// 注意:这里必须遍历全图所有的边,而不只是像Dijkstra那样遍历当前最近节点的邻居in edges:// [松弛操作]// 前提:起点到 u 必须是可达的 (dist[u] != infinity)// 且经由 u 到 v 的距离更短// 更新最短距离// 记录前驱节点// 3 . 负权环检测 (Negative Cycle Detection)// 再遍历一次所有边。如果此时还能进行松弛,说明图中存在负权环。// 因为正常的最短路径在 N-1 轮后应该已经收敛固定了。in edges:break // 发现负环,可以直接跳出// 4 . 返回结果"Error: Negative Weight Cycle Detected"
Prim 算法
Prim 算法 用于解决在加权连通图中寻找MST最小生成树 ,即找到连接图中所有顶点的一组边,使得这些边的总权重最小,且不形成任何环
Prim 算法与 Dijkstra 非常相似,主要区别在于:Dijkstra 关注的是从起点到当前节点的累积距离 ,而 Prim 关注的是当前节点连接到生成树的最小权重边
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 function Prim(G, s):// 1 . 初始化 (Initialization)// 【修改点 1 :dist 的含义变了】// 在 Dijkstra 中,dist 代表“离起点的累积距离”// 在 Prim 中,dist 代表“离生成树的最小距离 (Cut value)”1 到 N:// 源点进入树的代价为 0 0 // 初始化最小堆0 , s) )// [新增] 标记数组,用于判断节点是否已经加入了 MST// 虽然通过 lazy check 也能运作,但加上 visited 逻辑更严谨且能防止环// 2 . 主循环 (Processing)// 弹出堆顶元素:离“生成树”最近的节点// [关键优化:懒惰删除检查]// 如果该节点已经在 MST 中(或者这是一个过时的更差权重记录),跳过continue // 将 u 标记为正式加入 MST// 3 . 遍历邻居并更新 (Traverse Neighbors & Update)in G[u]:// 如果 v 已经在 MST 中,则不需要处理(防止成环)continue // 【修改点 2 :核心逻辑变化】// Dijkstra: new_dist ← dist[u] + w (我们要的是累积路径)// Prim: new_dist ← w (我们要的只是这条边的权重)// 如果这条边 (u, v) 的权重 w 小于 v 当前记录的“入树最小代价”// 更新 v 的最小入树代价// 记录前驱节点(表明 v 是通过 u 连入树的)// 将更新后的代价和节点推入堆中
Kruskal 算法
Kruskal算法 是图论中另一种寻找最小生成树 (MST) 的经典贪心算法,它不关心从哪个点开始,而是直接着眼于边 ,按照权重的从小到大,把边一条条加进来,直到所有点都连通
通过使用并查集 来判断两个点是否已经连通,初始时每个点一个集合,在连通两点时合并两点属于的集合,从而根据两点是否属于一个集合来判断两点是否连通
Prim 算法适合稠密图(边很多),Kruskal 算法适合稀疏图(边较少)
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Kruskal(G) :Make_Set(v ) in non-decreasing orderFind_Set(u ) != Find_Set(v ) :Union(u , v ) == |V | - 1: BREAK RETURN A
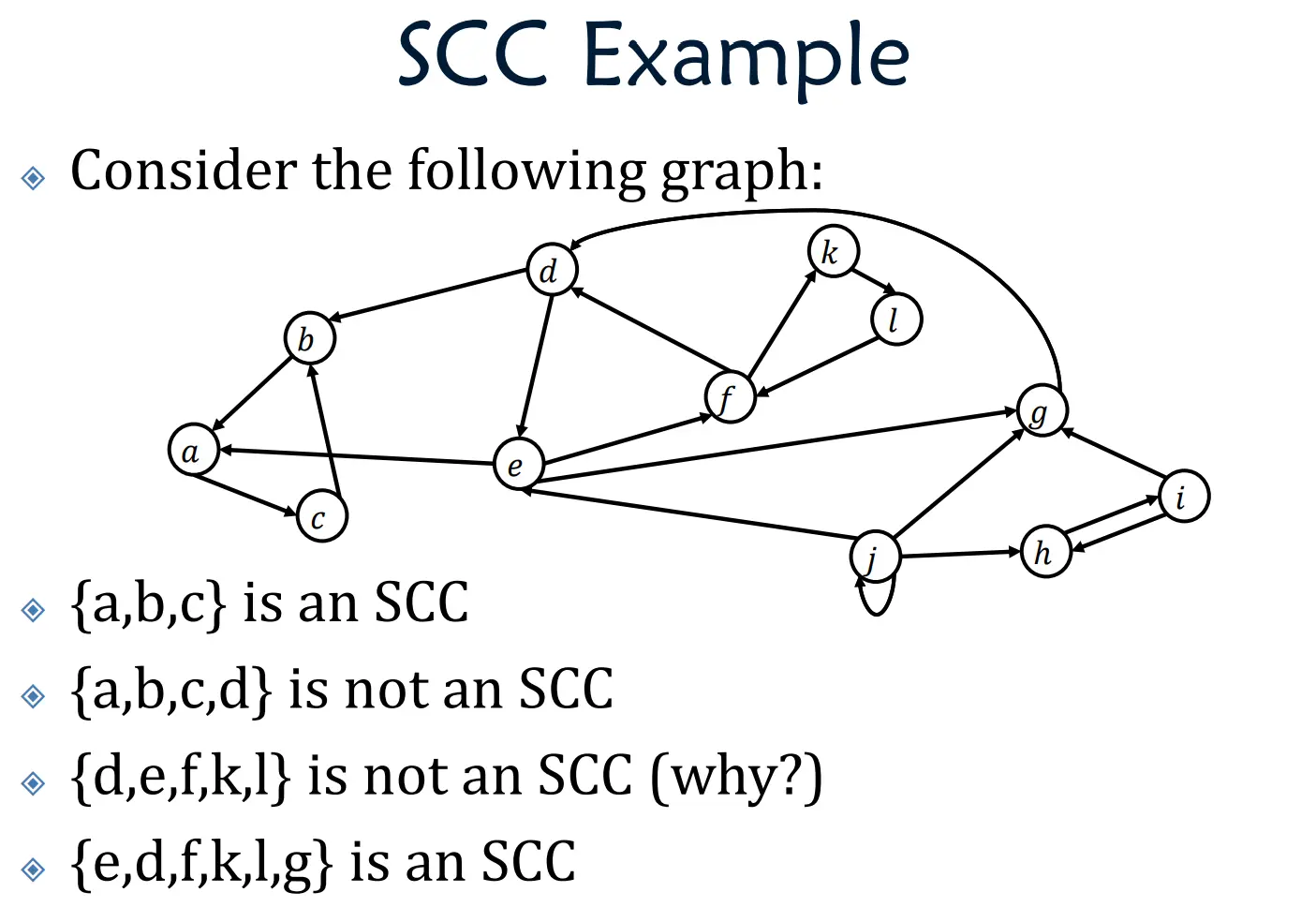
SCC 强连通分量
强连通分量 (Strongly Connected Component, 简称 SCC) 是有向图 (Directed Graph)中一个非常重要的概念
1. 核心特征
必须是有向图 :无向图叫“连通分量”,有向图才叫“强连通分量”互相可达 :集合内任意两个点 u , v u, v u , v u → v u \to v u → v v → u v \to u v → u 极大性 :你不能再往这个集合里添加任何一个新的点,否则就不满足“互相可达”的性质了
2. 求解 SCC(Kosaraju 算法)
Kosaraju 算法 是用来求解有向图中 强连通分量 (SCC) 的一种算法,虽然它的效率比Tarjan 算法 稍微慢一点点(因为它需要对图进行两次遍历,而 Tarjan 只需要一次),但是它的逻辑非常直观,容易理解和记忆
核心思想:两次 DFS
第一次 DFS(正向图) :确定的“拓扑顺序”。我们要找出哪些点是“上游”的,哪些是“下游”的。我们把点按照“完成访问的时间 ”压入一个栈中反向图(Transpose Graph) :将原图中所有的边方向反转(u → v u \to v u → v v → u v \to u v → u 第二次 DFS(反向图) :按照栈中弹出的顺序(从“上游”开始),在反向图中进行 DFS。每次能遍历到的所有点,就是一个强连通分量
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 Algorithm Kosaraju(Graph G, int N) :[] visited = new Boolean[N] initialized to false function DFS1(u ) :[u ] = true for each v in G .[u ] :if not visited[v ] :DFS1(v ) for i from 1 to N:if not visited[i ] :DFS1(i ) TransposeGraph(G) new Boolean[N] initialized to false function DFS2(u , currentSCC ) :[u ] = true for each v in revG.adj[u ] :if not visited[v ] :DFS2(v , currentSCC ) while stack is not empty:() if not visited[u ] :new List() DFS2(u , component )
Java:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 import java.util.*;import java.io.*;public class KosarajuAlgo {static int n, m;static ArrayList<Integer>[] adj; static ArrayList<Integer>[] revAdj; static boolean [] visited; static Stack<Integer> stack; static List<List<Integer>> sccResults; public static void main (String[] args) {5 ;5 ;new ArrayList [n + 1 ];new ArrayList [n + 1 ];for (int i = 1 ; i <= n; i++) {new ArrayList <>();new ArrayList <>();1 , 2 );2 , 3 );3 , 1 );3 , 4 );4 , 5 );"总共有 " + sccResults.size() + " 个强连通分量:" );for (int i = 0 ; i < sccResults.size(); i++) {"SCC #" + (i + 1 ) + ": " + sccResults.get(i));static void addEdge (int u, int v) {static void solveKosaraju () {new Stack <>();new boolean [n + 1 ];for (int i = 1 ; i <= n; i++) {if (!visited[i]) {false );new ArrayList <>();while (!stack.isEmpty()) {int u = stack.pop();if (!visited[u]) {new ArrayList <>();static void dfs1 (int u) {true ;for (int v : adj[u]) {if (!visited[v]) {static void dfs2 (int u, List<Integer> currentSCC) {true ;for (int v : revAdj[u]) {if (!visited[v]) {
杂鱼 ❤~
主定理
T ( n ) = a T ( n / b ) + c n d T(n) = aT(n/b) + cn^d
T ( n ) = a T ( n / b ) + c n d
想象你在处理一个大任务(比如整理 1000 份文件):
n n n a a a a a a b b b 1 / b 1/b 1/ b c n d cn^d c n d
三种情况
我们需要比较 a a a b d b^d b d
情况 1:子问题太多了 (叶子赢了)
T ( n ) = Θ ( n log b a ) T(n) = \Theta(n^{\log_b a})
T ( n ) = Θ ( n l o g b a )
(注意:log b a \log_b a log b a
情况 2:完美平衡
T ( n ) = Θ ( n d log n ) T(n) = \Theta(n^d \log n)
T ( n ) = Θ ( n d log n )
情况 3:合并代价太大
T ( n ) = Θ ( n d ) T(n) = \Theta(n^d)
T ( n ) = Θ ( n d )
例子 1:归并排序 (Merge Sort)
公式:T ( n ) = 2 T ( n / 2 ) + n T(n) = 2T(n/2) + n T ( n ) = 2 T ( n /2 ) + n
参数: a = 2 a=2 a = 2 b = 2 b=2 b = 2 c n 1 cn^1 c n 1 O ( n ) O(n) O ( n ) d = 1 d=1 d = 1 比较:
a = 2 a = 2 a = 2 b d = 2 1 = 2 b^d = 2^1 = 2 b d = 2 1 = 2 结论: 2 = 2 2 = 2 2 = 2 情况 2 (平衡型) 。
答案: T ( n ) = Θ ( n 1 log n ) = Θ ( n log n ) T(n) = \Theta(n^1 \log n) = \Theta(n \log n) T ( n ) = Θ ( n 1 log n ) = Θ ( n log n )
例子 2:二分查找 (Binary Search)
公式:T ( n ) = 1 T ( n / 2 ) + c T(n) = 1T(n/2) + c T ( n ) = 1 T ( n /2 ) + c
参数: a = 1 a=1 a = 1 b = 2 b=2 b = 2 c = c ⋅ n 0 c = c \cdot n^0 c = c ⋅ n 0 d = 0 d=0 d = 0 比较:
a = 1 a = 1 a = 1 b d = 2 0 = 1 b^d = 2^0 = 1 b d = 2 0 = 1 结论: 1 = 1 1 = 1 1 = 1 情况 2 (平衡型) 。
答案: T ( n ) = Θ ( n 0 log n ) = Θ ( log n ) T(n) = \Theta(n^0 \log n) = \Theta(\log n) T ( n ) = Θ ( n 0 log n ) = Θ ( log n )
Rabin-Karp && 滚动哈希
Rabin-Karp 的精髓在于如何在 O ( 1 ) O(1) O ( 1 )
示例:
设定环境
字符映射 (Mapping):
我们将 4 个字符映射为 4 个整数:
进制 (Base):4
(因为只有 4 种字符,类似二进制、十六进制,这里我们用四进制)。
模数 (Modulus Q Q Q
(为了演示方便,选一个很小的质数,方便心算验证)。
任务 :
文本 (Text) : C A T G C模式 (Pattern) : A T G窗口长度 (m m m : 3
第一步:准备工作
在开始滚动之前,我们需要算一个常数 h h h
公式:h = Base m − 1 ( m o d Q ) h = \text{Base}^{m-1} \pmod Q h = Base m − 1 ( mod Q )
B a s e = 4 Base = 4 B a se = 4 m − 1 = 2 m - 1 = 2 m − 1 = 2 Q = 11 Q = 11 Q = 11
计算:
h = 4 2 ( m o d 11 ) = 16 ( m o d 11 ) = 5 h = 4^2 \pmod{11} = 16 \pmod{11} = \mathbf{5}
h = 4 2 ( mod 11 ) = 16 ( mod 11 ) = 5
(记住这个 5,后面每次移除旧字符时都要用到它)
第二步:计算目标(模式串)的哈希
我们要找的是 A T G,对应数值:1, 4, 3( 143 ) 4 (143)_4 ( 143 ) 4
1 ⋅ 4 2 + 4 ⋅ 4 1 + 3 ⋅ 4 0 1 \cdot 4^2 + 4 \cdot 4^1 + 3 \cdot 4^0
1 ⋅ 4 2 + 4 ⋅ 4 1 + 3 ⋅ 4 0
计算过程:
1 ⋅ 16 = 16 1 \cdot 16 = 16 1 ⋅ 16 = 16 4 ⋅ 4 = 16 4 \cdot 4 = 16 4 ⋅ 4 = 16 3 ⋅ 1 = 3 3 \cdot 1 = 3 3 ⋅ 1 = 3 和 = 16 + 16 + 3 = 35 = 16 + 16 + 3 = 35 = 16 + 16 + 3 = 35
取模:
H t a r g e t = 35 ( m o d 11 ) = 2 H_{target} = 35 \pmod{11} = \mathbf{2}
H t a r g e t = 35 ( mod 11 ) = 2
我们的目标就是找到哈希值为 2 的窗口。
第三步:初始化第一个窗口
文本的开头是 C A T,对应数值:2, 1, 4
计算这个四进制数 ( 214 ) 4 (214)_4 ( 214 ) 4
2 ⋅ 4 2 + 1 ⋅ 4 1 + 4 ⋅ 4 0 2 \cdot 4^2 + 1 \cdot 4^1 + 4 \cdot 4^0
2 ⋅ 4 2 + 1 ⋅ 4 1 + 4 ⋅ 4 0
= 32 + 4 + 4 = 40 = 32 + 4 + 4 = 40 = 32 + 4 + 4 = 40
取模:
H c u r r = 40 ( m o d 11 ) = 7 H_{curr} = 40 \pmod{11} = \mathbf{7}
H c u rr = 40 ( mod 11 ) = 7
比较:
当前哈希是 7,目标是 2。
7 ≠ 2 7 \neq 2 7 = 2
第四步:滚动哈希 (关键步骤)
我们将窗口从 [C A T] 滑动到 [A T G]。
旧哈希 (H o l d H_{old} H o l d : 7移出字符 : C (对应数值 2 )移入字符 : G (对应数值 3 )进制 (B a s e Base B a se : 4高位权重 (h h h : 5模数 (Q Q Q : 11
公式回顾:
H n e w = ( ( H o l d − 移出 ⋅ h ) ⋅ B a s e + 移入 ) ( m o d Q ) H_{new} = \left( (H_{old} - \text{移出} \cdot h) \cdot Base + \text{移入} \right) \pmod Q
H n e w = ( ( H o l d − 移出 ⋅ h ) ⋅ B a se + 移入 ) ( mod Q )
详细计算步骤:
移除最高位 (Remove High):
H o l d − ( 数值 C ⋅ h ) H_{old} - (\text{数值}_C \cdot h)
H o l d − ( 数值 C ⋅ h )
= 7 − ( 2 ⋅ 5 ) = 7 - (2 \cdot 5)
= 7 − ( 2 ⋅ 5 )
= 7 − 10 = − 3 = 7 - 10 = \mathbf{-3}
= 7 − 10 = − 3
关键点:出现负数了!
在计算机取模运算中,负数处理要很小心。我们通常加上一个模数 Q Q Q
− 3 ( m o d 11 ) -3 \pmod{11} − 3 ( mod 11 ) ( − 3 + 11 ) ( m o d 11 ) = 8 (-3 + 11) \pmod{11} = \mathbf{8} ( − 3 + 11 ) ( mod 11 ) = 8
(现在结果是 8)
左移一位 (Shift):
相当于乘以进制 Base。
8 ⋅ 4 = 32 8 \cdot 4 = 32
8 ⋅ 4 = 32
为了防止数字过大,这里可以随时取模(也可以最后取,结果一样)。
32 ( m o d 11 ) = 10 32 \pmod{11} = \mathbf{10}
32 ( mod 11 ) = 10
(现在结果是 10,这代表了 ‘AT’ 部分的哈希)
加入最低位 (Add Low):
加上新进来的字符 G (数值 3)
10 + 3 = 13 10 + 3 = 13
10 + 3 = 13
最终取模:
13 ( m o d 11 ) = 2 13 \pmod{11} = \mathbf{2}
13 ( mod 11 ) = 2
结果: 新窗口 A T G 的哈希值是 2
第五步:验证
当前窗口哈希:2
目标模式哈希:2
匹配成功! (Hash Hit)
最后一步是二次确认(防止哈希冲突):