VLA-RTC:[Arxiv 2512.01031] VLASH
VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference
作者: Jiaming Tang, Yufei Sun, Yilong Zhao, Shang Yang, Yujun Lin, Zhuoyang Zhang, James Hou, Yao Lu, Zhijian Liu, Song Han
机构: MIT, NVIDIA, Tsinghua University, UC Berkeley, UCSD, Caltech
期刊: arXiv 2025
链接: arXiv 2512.01031 | 项目代码
一句话总结
VLASH 通过在推理前先用旧 chunk 将 robot state 前滚到执行时刻,并配合偏移增强微调让模型真正学会利用 future state,从而在几乎不增加运行时开销、不改主干架构的前提下,实现平滑、稳定且快速的异步控制;此外还可结合 action quantization 进一步压缩执行时间。
核心贡献
- Future-state-aware async inference: 不直接在 stale state 上预测,而是先用旧 chunk 把 robot state roll forward 到执行时刻。
- 训练时 offset augmentation: 固定视觉 observation、联动偏移 state 与 target action,逼模型真正学会使用 proprioceptive state。
- Shared-observation fine-tuning: 多个 offset 共享一次 observation 编码,用 block-sparse attention 明显降低 fine-tuning 成本。
- Action quantization: 在异步推理已经隐藏模型延迟之后,进一步通过action合并压缩执行时间(速度提升主要来源)
📖 批读导航
| Section | 内容 |
|---|---|
| 00 - Abstract | 摘要与全文定位:future-state-aware async inference |
| 01 - Introduction | 异步推理动机、prediction-execution misalignment、和 RTC/A2C2 的位置关系 |
| 02 - Related Work | VLA、异步推理与 concurrent work 的定位 |
| 03 - Background | H / K / Δ 定义与 prediction interval / execution interval 失配 |
| 04 - Method | future-state awareness、offset augmentation、shared observation、action quantization |
| 05 - Experiments | Kinetix、LIBERO、真实机器人、reaction speed、fine-tuning efficiency |
| 06 - Conclusion | 方法边界与整体结论 |
| 07 - Appendix | SmolVLA 泛化、超参数、补充视频与架构细节 |
关键数字
| 指标 | 数值 |
|---|---|
| 相对同步推理速度提升 | 最高 2.03x |
| reaction latency 降低 | 最高 17.4x |
| Kinetix 延迟 4 步成功率 | 81.7% |
| 相对 Naive Async 的提升 | +30.5 个百分点 |
| shared-observation fine-tuning 单步加速 | 3.26x |
| SmolVLA 在 LIBERO 的附录 speedup | 最高 1.35x |
方法概览
1 | |
与相关方法对比
| 方法 | 核心机制 | 需要训练? | 额外运行时开销 |
|---|---|---|---|
| Synchronous | 执行完停下等 | 否 | 无 |
| Naive Async | 收到新 chunk 立马切换 | 否 | 无 (但会失稳) |
| A2C2 | 增加额外的 residual correction head | 是 (只训小头) | 有 (额外的网络前向) |
| RTC | 运行时 Inpainting + soft mask | 否 | 有 (额外的 diffusion guidance) |
| VLASH | 推理前状态前滚 + 训练时 offset 增强 | 是 | 几乎无额外开销 |
📊 Citation Landscape
TLDR (Semantic Scholar): VLASH is proposed, a general asynchronous inference framework for VLAs that delivers smooth, accurate, and fast reaction control without additional overhead or architectural changes and empowers VLAs to handle fast-reaction, high-precision tasks such as playing ping-pong and playing whack-a-mole, where traditional synchronous inference fails.
引用统计: 参考文献 33 篇 | 被引 15 次 | Influential Citations: 3
参考文献分组 (Top 5 per category, by citations)
VLA Foundations / Generalist Policies
| 论文 | 年份 | 引用 |
|---|---|---|
| RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control | 2023 | 2668 |
| OpenVLA: An Open-Source Vision-Language-Action Model | 2024 | 1869 |
| π0: A Vision-Language-Action Flow Model for General Robot Control | 2024 | 1365 |
| π0.5: a Vision-Language-Action Model with Open-World Generalization | 2025 | 669 |
| GR00T N1: An Open Foundation Model for Generalist Humanoid Robots | 2025 | 595 |
Real-Time / Asynchronous Inference
| 论文 | 年份 | 引用 |
|---|---|---|
| SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics | 2025 | 220 |
| Real-Time Execution of Action Chunking Flow Policies | 2025 | 77 |
| Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better | 2025 | 68 |
| Running VLAs at Real-time Speed | 2025 | 14 |
| Leave No Observation Behind: Real-time Correction for VLA Action Chunks | 2025 | 7 |
Benchmarks / Data / Embodiment
| 论文 | 年份 | 引用 |
|---|---|---|
| LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning | 2023 | 685 |
| DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset | 2024 | 620 |
| Gemini Robotics: Bringing AI into the Physical World | 2025 | 268 |
| HITTER: A Humanoid Table Tennis Robot via Hierarchical Planning and Learning | 2025 | 31 |
| Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks | 2024 | 27 |
Efficiency / Systems / Infrastructure
| 论文 | 年份 | 引用 |
|---|---|---|
| FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness | 2022 | 3897 |
| MLP-Mixer: An all-MLP Architecture for Vision | 2021 | 3470 |
| FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning | 2023 | 2424 |
| SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models | 2022 | 1403 |
| PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation | 2024 | 1015 |
推荐论文(Semantic Scholar Recommendations)
| 论文 | 年份 | 引用 | arXiv |
|---|---|---|---|
| RL-VLA3: Reinforcement Learning VLA Accelerating via Full Asynchronism | 2026 | 2 | 2602.05765 |
| FASTER: Rethinking Real-Time Flow VLAs | 2026 | 0 | 2603.19199 |
| AsyncVLA: An Asynchronous VLA for Fast and Robust Navigation on the Edge | 2026 | 3 | 2602.13476 |
| StreamingVLA: Streaming Vision-Language-Action Model with Action Flow Matching and Adaptive Early Observation | 2026 | 0 | 2603.28565 |
| StreamVLA: Breaking the Reason-Act Cycle via Completion-State Gating | 2026 | 0 | 2602.01100 |
| ProbeFlow: Training-Free Adaptive Flow Matching for Vision-Language-Action Models | 2026 | 0 | 2603.17850 |
| FUTURE-VLA: Forecasting Unified Trajectories Under Real-time Execution | 2026 | 0 | 2602.15882 |
| Efficient Long-Horizon Vision-Language-Action Models via Static-Dynamic Disentanglement | 2026 | 1 | 2602.03983 |
🔗 相关链接
Abstract
📌 预览
摘要把整篇论文压缩成一句话:异步推理真正的问题不是“边切 chunk 边抖”,而是模型用旧 state 生成了未来才会执行的动作。VLASH 的核心是把这个 state 对齐问题前移到 conditioning 和 fine-tuning 阶段处理。
Vision-Language-Action models (VLAs) are becoming increasingly capable across diverse robotic tasks. However, their real-world deployment remains slow and inefficient: demonstration videos are often sped up by to appear smooth, with noticeable action stalls and delayed reactions to environmental changes. Asynchronous inference offers a promising solution to achieve continuous and low-latency control by enabling robots to execute actions and perform inference simultaneously. However, because the robot and environment continue to evolve during inference, a temporal misalignment arises between the prediction and execution intervals. This leads to significant action instability, while existing methods either degrade accuracy or introduce runtime overhead to mitigate it. We propose VLASH, a general asynchronous inference framework for VLAs that delivers smooth, accurate, and fast reaction control without additional overhead or architectural changes. VLASH estimates the future execution-time state by rolling the robot state forward with the previously generated action chunk, thereby bridging the gap between prediction and execution. Experiments show that VLASH achieves up to speedup and reduces reaction latency by up to compared to synchronous inference while fully preserving the original accuracy. Moreover, it empowers VLAs to handle fast-reaction, high-precision tasks such as playing ping-pong and playing whack-a-mole, where traditional synchronous inference fails.
💡 Abstract 批读:
- 问题: 作者先把 real-time VLA deployment 的核心矛盾讲清楚了:同步推理会让机器人出现 action stalls 和 delayed reactions;但一旦改成异步推理,又会遇到 prediction interval 与 execution interval 不一致的问题,本质上是在用“旧时刻看到的 state”生成“未来时刻才会执行的动作”。
- 方法: VLASH 的核心不是在运行时修补动作,而是在动作生成前先把 robot state 前滚到预计执行时刻。具体做法是利用上一个 action chunk 中已知但尚未执行完的动作,把本体状态 roll forward,构造 future execution-time state,再据此生成下一个 chunk。
- 关键卖点: 这篇摘要反复强调 without additional overhead or architectural changes。意思是它不像 RTC 那样需要额外的 runtime inpainting,也不像某些 concurrent work 那样依赖额外预测头或复杂调度,而是把主要工作前移到 conditioning 与 fine-tuning 阶段完成。
- 为什么这样有效: 作者的判断是,在异步控制里最致命的错位往往先发生在 robot proprioceptive state,而不是每个视觉像素都必须被未来观测替换。只要模型在生成动作时“站在执行时刻的本体状态上思考”,控制稳定性就会显著改善。
- 结果: 摘要给出的 headline 很集中:最高
2.03xspeedup、最高17.4xreaction latency reduction,并且能把 VLA 推到 ping-pong、whack-a-mole 这类高动态高精度任务上。这里传递的不是单一 benchmark 提升,而是“VLA 终于能从慢速演示走向实时互动”的定位。- 一句话翻译: 由于机器人的状态和环境在推理期间不断变化,导致预测区间和执行区间之间产生时间错位。
🔖 Section 总结
核心洞察
- VLASH 重新定义了 async 的核心问题: 真正需要修的不是 chunk 之间表面上的衔接,而是 prediction-time state 与 execution-time state 的错位。
- 它和 RTC 的路线不同: RTC 是在运行时对将要执行的 chunk 做 freeze + inpainting;VLASH 则是在生成前把 state 对齐,尽量不把额外计算负担留到部署端。
- 摘要里的 headline 需要分开理解:
2.03x说的是整体执行速度,17.4x说的是 reaction latency,这两个数字共同服务于“更快且更灵敏”,但不是同一个指标。 - 方法成立的隐含前提: 作者默认只修正 robot state 就足以解决大部分 async instability,这也是全文后面需要实验支撑的关键假设。
- 对实时控制的意义: 如果这个假设成立,那么大模型 VLA 就不必靠降模型规模或增加 runtime 修补模块来换实时性,而是可以直接迈向高动态物理交互任务。
1 Introduction
📌 预览
Introduction 先从同步推理的停顿问题切入,再说明异步推理虽然能消除 stall,却会带来 prediction-execution misalignment。然后作者顺势给出 VLASH 的定位:不用改模型结构,也不增加运行时开销,通过 future-state-aware conditioning 让 VLA 真正可用于实时控制。
Recent advances in Vision-Language-Action models (VLAs) such as [16], Gemini [1, 34] and [26] have demonstrated remarkable capabilities in solving complex robotic tasks. In real-world deployment, these models are typically executed under a synchronous inference paradigm: the robot first performs model inference to generate an action chunk [41], then sequentially executes the actions before initiating the next inference cycle. This sequential pipeline introduces action stalls and delayed reactions to environmental changes, since the model remains idle during action execution and cannot update its perception in real time [4]. As a result, many VLA demonstration videos are sped up by several times to mask the discontinuous and slow motion.
💡 开场批读: 介绍“先想后动、想完再动” 的同步推理导致两个严重问题
- 动作卡顿(action stalls) —— 模型在执行动作期间是空闲的
- 对环境变化反应迟钝 —— 无法实时更新感知
To prevent this stop-and-go behavior, researchers have proposed asynchronous inference [4, 24, 29, 31]. In a nutshell, asynchronous inference allows the robot to execute the current action chunk while simultaneously performing inference for the next one. Because the execution duration of an action chunk is typically longer than the model inference time, the robot can immediately switch to the next chunk once the inference completes, avoiding idle period between chunks [4, 24, 29, 31]. This design eliminates action stalls and allows the robot to perform smooth, continuous motion. Moreover, since inference is performed continuously, the robot can maintain real-time perception and thus react to environmental changes more promptly and accurately [4, 24]. In summary, asynchronous inference provides a promising way to achieve smooth, accurate, and fast reaction control for VLAs.
💡 动机批注: 第二段说明 async inference 的吸引力很直接:一边执行当前 chunk,一边准备下一段动作。只要执行时间长于推理时间,就能显著减少 idle period,同时提升对环境变化的响应频率,持续进行推理,能实时感知环境,反应更快、更准确

Figure 1. VLASH enables VLA to play ping-pong rallies with humans. Snapshots showing [16] with VLASH successfully tracking and striking a fast-moving ping-pong ball during a rally. The robot initiates its reaction by the third frame, demonstrating low-latency perception-to-action response. The task requires both fast reaction and smooth continuous motion, which are enabled by our asynchronous inference with future-state-awareness. Under synchronous inference, the robot fails to achieve this dynamic interaction.
💡 Figure 1 批读: 图中展示的是 π0.5 模型在使用 VLASH 后,能够成功追踪并击打快速移动的乒乓球:让 VLA 在高动态、高精度任务里真正做到连续反应。机器人在第三帧就做出了反应,体现了极低的感知-动作延迟。

Figure 2. Prediction-execution misalignment in asynchronous inference. Due to inference delay , the model predicts actions for the prediction interval but they execute during the execution interval .
💡 Figure 2 批读: Figure 2 把 async 的根本矛盾画得很清楚:模型在区间
[t, t+K)看到环境并做预测,但因为推理耗时Δ,动作实际落地在区间[t+Δ, t+Δ+K)。只要Δ > 0,这种“用旧状态控制未来世界”的时间错位就是不可避免的根本性挑战(fundamental challenge)。
However, asynchronous inference faces a fundamental challenge that makes it unstable and inaccurate in practice. Since both the robot and the environment continue to evolve during inference, a temporal misalignment arises between the prediction interval starting when inference begins and the execution interval starting when inference finishes [4, 29]. As a result, the newly generated action misaligns with the robot’s execution-time state and environment, leading to severe instability and degraded control accuracy. For example, naive asynchronous inference reduces reaction latency but exhibits unstable and laggy control performance [4]. RTC [4] mitigates this by freezing the actions guaranteed to execute and inpainting the rest, but it introduces additional runtime overhead and complicates the deployment. In addition, current implementations [24, 29, 31] often require multi-threaded redesign of the inference framework to support asynchronous inference efficiently. Together, these create a significant barrier for the adoption of asynchronous inference for VLAs.
💡 核心矛盾: 这一段是对已有 async 方法痛点的总括。naive async 会直接失稳;RTC 通过 freezing + inpainting 缓解错位,但有额外开销;现有工程实现还常常依赖多线程重构,这些因素共同构成了 VLA 采用异步推理的重要障碍
To address these challenges, we propose VLASH, a general asynchronous inference framework for VLAs that achieves smooth, accurate, and fast reaction control without additional overhead or architectural changes. In a nutshell, VLASH makes the model future-state-aware by accurately estimating the execution-time robot state using the previously issued action chunk, effectively bridging the gap between prediction and execution. VLASH integrates seamlessly into existing fine-tuning pipelines and introduces no additional cost or latency. With a clean and lightweight implementation, VLASH provides a full-stack asynchronous inference framework from fine-tuning to inference at deployment, making asynchronous control practical and easy to adopt for real-time VLA systems.
💡 VLASH 核心思想:
without additional overhead or architectural changes
VLASH 不是靠更重的运行时补丁,不是靠多加一个复杂模块,也不是靠改模型结构才起作用,保持轻量化
future-state-aware
VLASH 不是在动作已经生成之后再去“修动作”,而是在模型生成动作之前,就让模型看到更接近执行时刻的机器人状态,也就是把对齐问题前移到输入条件上
integrates seamlessly into existing fine-tuning pipelines
可以嵌进现有 VLA 微调和部署流程的框架
We build and evaluate VLASH across various VLA models, including [16] and SmolVLA [31]. On simulation benchmarks [25], VLASH achieves up to accuracy improvement compared to naive asynchronous inference and consistently outperforms all baselines. On real-world benchmarks [31], VLASH achieves up to speedup and reduces reaction latency by up to compared to synchronous inference while fully preserving the original accuracy. Beyond quantitative gains, VLASH demonstrates that large VLA models can handle fast-reaction, high-precision tasks such as playing ping-pong and playing whack-a-mole, which were previously infeasible under synchronous inference. We hope these results will inspire future research toward extending VLAs to more dynamic and physically interactive robotics.
💡 贡献总结: 仿真里最多
30.5%精度提升,真实世界里最多2.03x速度提升和17.4xreaction-latency 改善,同时还不损失原有精度
🔖 Section 总结
核心洞察
- 同步推理的 stop-and-go 是 VLA 真实部署中的第一层瓶颈
- 异步推理能解决停顿,但会引入更本质的时序错位(用旧环境控制新时刻的本体)
- VLASH 的切入点是“生成动作时看对 state”,而不是“执行动作时再补救”,这种预见性思路为降低部署开销指明了方向
- 对实时控制的意义: 未来的状态和当前的画面结合,能在不改模型的前提下实现零运行时惩罚的异步执行,这使得打乒乓球这样对低延迟要求极高的任务变得可能
2 Related Work
📌 预览
作者用两段话把本文放进两个脉络里:一是 generalist VLA 的发展,二是 VLA 异步推理的几条代表路线。读这一节的关键是弄清 VLASH 相比 RTC 和 A2C2 到底少做了什么、又多做了什么。
Vision-Language-Action Models (VLAs). Recent advances in Vision-Language-Action models have demonstrated remarkable capabilities in robotic manipulation by leveraging large-scale pretraining on diverse and internetscale vision-language data. Models such as [16], RT-2 [43], and [26], etc. [3, 19] combine visual encoders with large language models to enable generalist robotic policies that can follow natural language instructions and generalize across tasks and embodiments. These models are typically deployed under synchronous inference, where the robot waits for model inference to complete before executing actions, resulting in action stall and slow reaction to environmental changes [4, 29]. Our work addresses this limitation by enabling efficient asynchronous inference for VLAs.
💡 动机批注: 第一段只是很快交代背景:VLA 已经在通用操控上展现出很强能力,但默认部署范式仍是同步推理,因此 stall 和慢反应依旧是现实痛点。
Asynchronous VLA Inference. Asynchronous inference offers a promising way to eliminate action stalls and improve reaction speed of VLAs, but existing approaches still face significant barriers to adoption in the VLA community. SmolVLA [31] implements naive asynchronous inference by directly switching to new action chunks, but this causes severe prediction-execution misalignment and unstable control. Real-time Chunking (RTC) [4] mitigates this by freezing actions guaranteed to execute and inpainting the remaining actions, but this introduces additional runtime overhead for the inpainting process and complicates deployment. A concurrent work, A2C2 [29], adds an additional correction head to the model to mitigate the prediction-execution misalignment, but this also introduces runtime overhead and requires architecture changes to the model. In contrast, our method achieves asynchronous inference through future-state-awareness without additional overhead.
💡 方法对比:
- SmolVLA / naive async: 直接切换新 chunk,优点是简单,缺点是 prediction-execution misalignment 最严重。
- RTC: 承认错位问题存在,在运行时通过 freeze + inpainting 修补,但代价是额外开销和更复杂部署。
- A2C2: 不做 inpainting,而是给模型加 correction head,本质上仍是“额外模块换稳定性”。
- VLASH: 不在运行时补救,也不加额外头,而是通过 future-state-aware conditioning 改变模型生成动作时看的 state。
- 所以 VLASH 的卖点不只是“效果更好”,而是“少做了很多额外的事”

Figure 3. Comparison between VLASH and existing methods. (a) Synchronous inference: the robot stalls during inference, introducing slow reactions. (b) Naive async: the model predicts based on stale state while execution begins at future state , causing misalignment and discontinuity. © VLASH rolls forward the robot state ) and condition on the execution-time state, achieving fast reaction and smooth actions.
💡 技术细节: Figure 3 用一张图把三条路线的差异画出来了。Synchronous 的问题是停顿,naive async 的问题是 stale state,VLASH 的思路则是先把 robot state 推进到真正开始执行新 chunk 的时刻,再基于执行时刻的 state 生成新动作
🔖 Section 总结
核心洞察
- VLASH 不是否定异步推理,而是在异步范式内部重新定义 conditioning(状态条件输入)。
- 与 RTC 相比,它少了运行时 inpainting;与 A2C2 相比,它少了额外 correction head。
- 对实时控制的意义: 作者试图证明,只要对齐 state 本身,就足以消解大部分由于异步引起的不稳定,这意味着我们不需要复杂的运行时修复组件,即可享受低延迟带来的操作红利。
3 Background
📌 预览
Background 把后文所有符号先定下来: 是 prediction horizon, 是 execution horizon, 是以控制步计的推理延迟。真正要记住的只有一句话:异步推理时,动作生成区间和动作落地区间并不重合。
Action chunking policy. We consider an action chunking policy [16, 31, 42], where is the environment observation (e.g., image, multi-view visual input), is the robot state (e.g., joint positions, gripper state), and is the controller timestep. At each timestep , the policy generates a chunk of future actions
💡 符号定义: 是一次预测多远, 是一次先执行多少, 是推理延迟多少个控制步。后面所有关于异步稳定性的问题,本质上都来自这三个量之间的相对关系。
where is the number of actions in the chunk. We refer to as the prediction horizon.
💡 第一层定义: 不是单步动作,而是从 开始的一整段未来动作; 对应 prediction horizon,也就是模型一次向前规划的长度。接下来作者会再引入 ,把“预测多少”和“实际先执行多少”区分开。
as the time interval where the first actions from the action chunk are planned to be executed. During actual execution, however, the actions from will start being applied later due to inference latency [4, 31].
💡 第二层定义: 实际系统里通常不会把 个动作全执行完,而是只先执行前 个动作,再重新推理,所以 是 execution horizon。于是模型在时刻 生成 时,默认对应的是 prediction interval 。
Let be the inference latency measured in control steps. Then the actions from are actually executed on the robot over the execution interval
💡 关键转折: 真正的问题从这里开始。作者把推理延迟写成 个控制步,而不是毫秒,这样后面讨论错位时就不依赖具体控制频率,而是直接落在控制时序本身。
Asynchronous inference and interval misalignment. With asynchronous inference, the robot continues executing the previous action chunk while computes in the background. As illustrated in Fig. 2, when , the action chunk is planned for the prediction interval but actually executed over the shifted execution interval . Intuitively, the actions in are not wrong for the original prediction interval . However, under asynchronous inference, by the time they are executed, the environment and robot state have changed, so the same action sequence is applied to a different state and scene, leading to unstable and discontinuous behavior [4, 29].
💡 核心结论: 这串动作本身并不是“预测错了”,它对原本的 prediction interval 是合理的;问题在于异步执行时,它真正落在了右移 步的 execution interval 上。于是同样的动作被施加到了一个已经变化过的 robot state 和 environment 上,这就是 lag、抖动和不连续的根源。
🔖 Section 总结
核心洞察
- 决定一次预测多远, 决定一次先执行多少, 决定时序错位有多严重。
- 异步(async)控制的本质不仅仅是“重叠计算与执行以变快”,更是“预测区间和执行区间发生了物理分离”。
- 对实时控制的意义: 明确这三个变量,是分析所有异步策略的基石;任何改善实时控制表现的方法,最终都在试图填平这 步带来的信息鸿沟。
4 VLASH
📌 预览
Method 是全文核心。作者实际上做了四件相互衔接的事:先在推理时用旧 chunk 把 robot state 前滚;再在 fine-tuning 阶段通过 offset augmentation 逼模型真正学会利用 future state;然后用 shared observation 降低多 offset 训练成本;最后再用 action quantization 压缩物理执行时间。
4.1 Future State Awareness
In asynchronous inference, the robot keeps moving while the VLA performs a forward pass, so the state at inference start generally differs from the state at which the new actions actually begin execution. Our key idea is to make the policy future-state-aware: instead of conditioning on the current robot state , we condition on the robot state at the beginning of the next execution interval .
💡 核心原理: 这一段是 VLASH 最核心的一句话:与其让模型看推理开始时刻的 ,不如直接给它看新 chunk 真正开始执行时刻的 。方法的本质是重新定义 conditioning 的时刻
Although the future environment observation is unknown, the robot state at the beginning of the execution interval is determined by the current robot state and the actions executed during the inference delay . As shown in Fig. 3©, when inference for the new chunk starts at state , the robot will still execute the remaining actions from the previous chunk before the new chunk is ready to take over. Since the actions are already known, we can roll the state forward under them to obtain the execution-time state. In the Fig. 3©, this corresponds to computing , which gives the robot state at the start of the execution interval.
💡 技术细节: 关键点在于未来 observation(环境画面)不可知,但未来 robot state(本体姿态)有一部分是可精确预测的,因为推理期间机器人还会继续执行旧 chunk 剩余的动作。于是作者只去 roll forward “系统自己能确定的那部分未来”。
During the forward pass, VLASH feeds both the current environment observation and this rolled-forward future state into the VLA. In this way, the model generates actions for the state at the execution-time rather than for the stale state at inference start, bridging the gap between prediction and execution in terms of robot state. While the future environment is still unknown, this mechanism mirrors how humans act under reaction delays: we react to the world with slightly outdated visual input, but use our internal body state to anticipate what we will do when the action actually takes effect. Thus, humans inherently have the ability to compensate for such reaction delay, and we expect VLAs to possess the same capability.
💡 直观类别: 这里的 human analogy 很绝。作者承认缺失未来视觉输入是不完美的,但强调人类在打球时也是这样:眼睛看到的画面总有延迟(outdated visual input),但大脑会用肌肉的本体感觉(internal body state)预测挥拍真正发力时的身体姿态。VLASH 就是想让 VLA 学会这种“用本体状态补偿视觉延迟”的生物本能。
4.2 Fine-tuning with Offsets to States and Actions
The future-state-awareness assumes that the VLA is able to leverage the rolled-forward robot state. However, we find that existing VLAs often fail to exploit this future state properly. Even more, current VLAs appear to largely rely on visual input and under-utilize the robot state. In our experiments with (Table 1), fine-tuning without state input (visual only) consistently outperforms fine-tuning with state input on LIBERO [23]. Therefore, simply feeding a future robot state at test time is insufficient to achieve accurate and stable asynchronous control.
💡 核心矛盾: 这一段其实揭示了只做 inference-time hack 会失败的原因。现有 VLA 往往重度依赖视觉特征(overfit to visual features)而很少真正听从 robot state。比如实验表明, 在 LIBERO 上甚至不输入 state 效果更好(visual-only 强于带 state)。所以,如果在推理时硬塞一个 future state,模型根本不懂怎么利用它来出动作。
Since large VLAs are almost always fine-tuned on downstream data before analogy, we design a training augmentation that can be seamlessly integrated into the standard fine-tuning stage with no additional overhead. We keep the architecture and fine-tuning pipeline unchanged, and only modify how training samples are constructed.
💡 技术细节: 因此 VLASH 不只是 inference trick,它还包含一个训练数据构造。作者强调不改架构、不改 fine-tuning pipeline,只改训练样本构造方式,这一点与 A2C2 的改头部设计形成对比。
Concretely, given a trajectory , standard fine-tuning trains the model to predict the action chunk from . We instead apply a simple temporal-offset augmentation with two key steps:
(i) Offset state and action together. We sample a random offset from a predefined range (e.g., and construct training targets from the future state and future action chunk on the same trajectory.
(ii) Fix the environment observation. For each timestep , we always use the same visual input when varying . Therefore, the model is trained to predict from the pair .
Under this scheme, the same image can correspond to different ground-truth actions depending on the offset robot state . To fit the data, the VLA is forced to attend to the state input rather than overfitting purely to visual features. In particular, it learns to interpret as a meaningful future state for action selection.
💡 核心原理: 先对照标准 fine-tuning 的输入输出形式,把“不同延迟下的未来对齐问题”提前注入到训练数据里,这两步 augmentation 的设计非常直接:
- 采样一个 offset ,使state 和 target action一起向未来偏移,用和未来动作块 做目标
- **observation 固定不动。**也就是说,变的是 state 和 action,不变的是同一帧图像
这样同一张图会配上不同的 state-action 对,逼模型不能只偷看视觉线索,必须认真去读 ,才能知道现在该出哪一个动作,这正是 offset augmentation 的训练信号来源
We randomly sample during training because, in practice, the same VLA may be deployed on hardware with different compute budgets, leading to different inference delays , and sometimes even in synchronous settings where there is no gap between prediction and execution. By training over a range of offsets, our augmentation makes the model compatible with different inference delays while preserving performance in the synchronous case. At deployment with asynchronous inference, we can then feed the rolled-forward execution-time state together with the current observation, and the fine-tuned VLA naturally leverages this future state to produce actions that are aligned and stable over the execution interval.
💡 技术实现: 随机采样 则是在为不同硬件预算、不同推理延迟做 domain randomization。这样得到的模型既能兼容同步场景,也能兼容不同程度的异步延迟。
4.3 Efficient Fine-tuning with Shared Observation
The temporal-offset augmentation creates multiple state-action pairs for the same observation . A naive implementation would treat each offset as a separate training example, i.e., run the VLA independently on for each sampled . This implementation is completely plug-and-play and can be seamlessly integrated into existing VLA fine-tuning pipeline. However, it repeatedly encodes the same observation for every offset, leaving substantial room for further efficiency gains.
💡 核心问题: 进入 4.3 之后,焦点从“能不能学会”转向“这样训练会不会太贵”。如果每个 offset 都单独跑一遍前向,那么最浪费的就是重复编码相同 observation。
Instead, we exploit the fact that all offsets share the same observation and design an efficient attention pattern that reuses the observation tokens across offsets in a single pass (Fig. 4). Concretely, we pack one observation and multiple offset branches into a single sequence:
💡 核心原理: 作者的工程优化点很自然:既然多个 offset 共享同一帧 observation,就把它们打包进同一个序列里,只让 observation 编码一次。
where each corresponds to one temporal offset. We then apply a block-sparse self-attention mask with the following structure:
💡 公式理解: 公式(4) 把一个共享的 放在最前面,后面接多个 offset branch 。它体现的不是新语义,而是训练时的并行批处理布局,让一个序列能同时计算多个延迟情况下的损失。
这里开始定义 block-sparse attention mask。在训练序列里打包了多个 offset,但它们不能串味:每个 offset 分支都能看到最前面共享的 observation token,同时只能看到自己分支内的 state-action token。这就像在做 batch inference,只是把多 batch 压缩进了一个 token 序列的注意力掩码里。
- All observation tokens (e.g., image tokens from two views and language prompt, about tokens for ) can attend to each other, as in standard VLA fine-tuning.
- For each offset branch, the state-action tokens can attend to all observation tokens and to tokens within the same offset, but cannot attend to tokens from other offsets.
💡 核心分析: 这两个 attention 约束合起来,就把“共享 observation、独立 offset”的结构编码进了 self-attention。它本质上相当于把多个样本拼成一个大样本,但避免了重复编码视觉 token。

Figure 4. Attention pattern for efficient fine-tuning with shared observation. We pack one shared observation and multiple offset branches into a single sequence. Blue and yellow cells indicate allowed attention, while gray cells indicate masked attention. Positional encodings of each offset branch are reassigned to start at the same index, equal to the length of observation tokens.
💡 图片解读: 可以把它理解成一个 attention 矩阵:
- 第 i 行:第 i 个 token 去看别人
- 第 j 列:第 j 个 token 被别人看
蓝色/黄色表示允许,灰色是被mask掉
- 左上角大块:observation 看 observation
- 每个 branch 朝左那块:branch 看 observation
- 每个 branch 自己对角线那块:branch 看自己
- branch 和 branch 之间的非对角块:灰色,表示不能互相看
This attention map, illustrated in Fig. 4, makes different offsets condition on a shared observation while remaining independent of each other. For each offset branch, the positional encodings of are assigned to start at the same index, equal to the length of observation tokens. From the model’s perspective, this is equivalent to training on multiple examples that share the same , but we only encode once.
For , an observation with two images and language prompt corresponds to tokens, while one state and action chunk are about tokens [16]. Therefore, packing offsets into a single sequence therefore increases the token length by only , while the number of effective training trajectories becomes larger. In practice, under the same effective batch size as standard fine-tuning, this method can significantly improve training efficiency by reusing each observation across multiple offset targets in a single pass.
💡 核心分析: 把每个 offset branch 的位置重新对齐到 observation token 之后,相当于让模型“感觉”自己在看多份共享同一 observation 的独立样本。 中 observation 大约 个 token,state + action chunk 只有 个 token,所以同时打包 5 个 offset,序列长度只增加约 ,有效训练样本却扩大 。
4.4 Action Quantization
With asynchronous inference and future-state-awareness, the model inference time is effectively hidden behind execution. Once this inference latency is removed, the overall speed of the system is primarily limited by how fast the robot can physically execute the action sequence. To push the execution speed further, we need to accelerate the motion itself.
💡 量化动机: 到这里作者认为推理延迟已经基本被隐藏在执行过程后面了,剩下的瓶颈就从“模型算得够不够快”转成“机器人本体动得够不够快”。
Our approach is to quantize actions, in analogy to weight quantization for LLMs [11, 22, 37]. State-of-the-art VLAs are typically trained on fine-grained teleoperation data (e.g., control with small deltas at each step) [3, 16], which leads to action sequences with high granularity. However, many short micro-movements are more precise than what is actually required to solve the tasks. In LLMs, 16-bit weights provide high numerical precision, but quantizing them to 8-bit or 4-bit can substantially accelerate inference with only a mild drop in accuracy [11, 22, 37]. We apply the same philosophy to robot control.
💡 降采样稀疏化: action quantization 的类比很有意思:像 LLM 里做 weight quantization 一样,这里把高频、细粒度的 micro-action 合并成更粗的 macro-action,用更少步数完成类似位移。

Figure 5. Action quantization for efficient execution. We group consecutive fine-grained micro-actions into coarser macro-actions to accelerate robot motion. The original trajectory with fine-grained actions (gray) is quantized into a shorter trajectory with macro-actions (black), where each macro-action summarizes consecutive fine-grained actions (e.g., for quantization factor ).
💡 技术细节: Figure 5 直观看到量化后的轨迹更稀疏。它不是让策略学新动作,而是把已有动作序列在执行时重新聚合成更长的步长。
Given a fine-grained action sequence , we group consecutive actions into coarser macro-actions. For a chosen quantization factor , we construct a new sequence where each macro-action summarizes a block of fine-grained actions. For delta actions, this can be implemented as
💡 公式理解: 公式(5) 把量化因子 写成了最直接的求和形式:。 越大,一次执行跨越的细粒度动作越多,速度也越快。
so that takes the robot approximately from the start state of to the end state of in a single, longer step. Fig. 5 illustrates this process: the original fine-grained trajectory (gray) is replaced by a shorter, quantized trajectory (black) with macro-actions , where .
💡 核心分析: 作者这里强调 macro-action 的语义:它大致把机器人从 的起点直接带到 的终点,因此跳过了一些中间 waypoint,这本质上是一个 inference-execution trade-off。
Executing macro-actions instead of all micro-actions increases the distance moved per control step, effectively speeding up the robot’s motion. The temporal granularity of control becomes coarser, but in many tasks the robot does not need to visit every intermediate waypoint explicitly; moving directly between sparser waypoints is sufficient to achieve the goal. As a result, action quantization offers a tunable speed-accuracy trade-off: small quantization factors behave like the original fine-grained policy, while larger factors yield progressively faster but less fine-grained motion. In practice, we select task-dependent quantization factors that maintain success rates close to the unquantized policy while substantially reducing the number of executed steps.
💡 实验结论: 最后一段给出一个很现实的结论:action quantization 并不是 VLASH 的核心对齐机制,但它决定了论文 headline 里的最大 speedup 能有多高,因为那部分收益来自执行步数本身的减少。
🔖 Section 总结
核心洞察
- roll-forward state 是推理时机制,offset augmentation 才是让这种 future state 真正被模型学会使用的训练机制。单纯前滚状态是不够的。
- shared observation 解决的是“多 offset 训练是否过贵”的工程问题,也是这个框架得以低成本落地的保障。
- action quantization 进一步压榨的是物理执行瓶颈,因此要和 future-state alignment 消除系统等待的收益分开理解。
- 对实时控制的意义: 只要模型被教会了关注“执行时刻”的自身状态,我们就不再需要在运行中途用复杂的修复算法去缝合动作,VLA 在极高的计算负载下也能“优雅地打提前量”。
5 Experiments
📌 预览
Experiments 主要回答四件事:VLASH 是否真的比同步/朴素异步更稳、更快;它在不同延迟和不同 VLA 上是否泛化;action quantization 带来的速度-精度权衡如何;以及 shared-observation 训练到底省了多少成本。读这一节时,最好把 Kinetix、LIBERO、真实机器人和 reaction-latency 表分开看。
We design experiments to investigate the following questions:
- Performance. How does our method compare to synchronous control, naive asynchronous and baselines in terms of accuracy and latency? (Sec. 5.1.1, Sec. 5.2) 2. Generalization. How well does our method generalize across different inference delays? Does it hurt the original model performance? How well does our method generalize across different VLAs? (Sec. 5.1.2) 3. Speed-accuracy trade-off. What is the speed-accuracy trade-off of action quantization at deployment? (Sec. 5.2) 4. Fine-tuning efficiency. How does our method compare to the standard fine-tuning in terms of training cost and data efficiency? How much the shared observation fine-tuning can reduce the training cost? (Sec. 5.3)
💡 核心分析: 四个 claim:方法有效、延迟泛化成立、执行可以继续提速、训练开销仍然可接受。
5.1 Simulated Evaluation
We evaluate VLASH on simulated robotic manipulation benchmarks including Kinetix [25] and LIBERO [23].
5.1.1 Kinetix
Experimental Setup. Kinetix [25] is a highly dynamic simulated robotic manipulation benchmark that demands asynchronous execution to handle rapidly changing environments. The tasks are designed to test dynamic reaction capabilities, including throwing, catching, and balancing.
Following the setup in RTC [4], we train action chunking flow policies with a prediction horizon of and a 4-layer MLP-Mixer [35] architecture for 32 epochs. We report average success rates across 12 tasks, each evaluated with 1,024 rollouts per data point, under simulated delays ranging from 0 to 4 steps. We compare against the following baselines:
💡 实现细节: Kinetix 是这篇最适合检验 async 的仿真环境,因为任务本身就强调 throwing、catching、balancing 这类动态反应,而不是缓慢、近静态的操控。
Kinetix 训练和评测设置:
H=8、4-layer MLP-Mixer、32 epochs、12 个高动态任务(如扔、接、平衡)、每点 1024 rollouts、延迟从 0 到 4 步。
-
Sync. This baseline serves as an optimal baseline for all tasks. The inference delay is explicitly set to 0 at all times.
-
Naive async. This baseline is the naive asynchronous inference baseline, which simply switches chunks as soon as the new one is ready [31].
-
RTC. This baseline is the Real-time Chunking [4], which freezes the actions guaranteed to execute and inpaints the rest. This introduces additional overhead at runtime.
💡 实验基线:
- Sync 是理论上界,因为它强行把 delay 设成 0。后面的 async 方法都可以理解为在尽量逼近这个上界
- Naive async 是最朴素的基线:新 chunk 一算完就切换,不做任何对齐或修正,因此最容易受到 stale state 影响
- RTC 在这里是最直接的强基线,因为它同样关注 prediction-execution misalignment,但走的是 runtime inpainting 路线

Figure 6. Performance on Kinetix benchmark. We evaluate the success rate under different execution horizons and inference delays . Left: Fixed inference delay with varying execution horizon . Right: Execution horizon adapts to inference delay, i.e., , with varying . For the Sync baseline, inference delay is always , but the execution horizon follows the same settings as other baselines for fair comparison.
💡 实验结论: Figure 6 是 Kinetix 的核心结果。左图看 execution horizon 变化,右图看 inference delay 增大时的鲁棒性;后者更能体现 VLASH 在大延迟下的稳定优势。
Results. As shown in Fig. 6, VLASH tracks the synchronous upper bound closely across execution horizons, while other baselines drop more noticeably as the execution horizon increases. When the inference delay increases, VLASH remains robust and consistently achieves high success rates, while RTC degrades rapidly and the Naive Async baseline collapses under larger delays. Notably, at inference delay of 4 steps, VLASH achieves success rate compared to only for Naive Async, which is a substantial accuracy improvement. Overall, VLASH effectively mitigates prediction-execution misalignment, delivering high success rates under asynchronous operation.
💡 核心洞察: 结果部分最值得记的是这组核心数字:在 delay=4 的极高延迟下,Naive Async 已经崩塌到了 51.2%,而 VLASH 仍然坚挺在 81.7%,带来了 +30.5% 的绝对精度提升。这证明了在面对极端的 prediction-execution misalignment 时,future-state alignment 的鲁棒性远超朴素方法。
5.1.2 LIBERO
Experimental Setup. We evaluate on the LIBERO benchmark [23], one of the popular benchmarks for evaluating VLA, which includes 4 different sub-benchmarks (Spatial, Object, Goal, and LIBERO-10) that contain 10 tasks each. We evaluate on 2 state-of-the-art VLAs: [16] and SmolVLA [31]. We report the performance by fine-tuning all models on the training dataset for 30K iterations with a batch size of 32. Following the setup in [16], we set the execution horizon to [10]. Since LIBERO tasks involve slowly changing environments with mild state transitions, different asynchronous methods behave similarly. Therefore, we focus our comparisons on synchronous inference to evaluate the effectiveness of VLASH under various inference delays. For time measurement, we use a laptop RTX 4090 GPU where the inference latency with 2 input images is . For synchronous inference, the time per action chunk is the sum of execution duration (166ms for steps at ) and inference time. For asynchronous inference, larger delays are needed to overlap with the inference latency, so the time per action chunk is: execution duration + max(0, inference time −
💡 动机批注: LIBERO 更偏向慢变化环境,因此不同 async 方法之间不会像 Kinetix 那样迅速拉开差距。这里的重点不在“谁更会追动态目标”,而在“VLASH 会不会破坏原本的操控精度,以及不同 delay 下能否保持合理的速度收益”。

Table 1. Performance on LIBERO benchmarks with different inference delays. We evaluate [16] across four LIBERO subbenchmarks (Spatial, Object, Goal, LIBERO-10) under various inference delays (0 to 4 steps). SR: average success rate; Steps: average execution steps to task completion; Time: completion time on a laptop RTX 4090 GPU (inference latency: for 2 images). Sync (w/o state): fine-tuned and evaluated with synchronous inference without robot state input.
💡 实验结论: Table 1 是
π0.5在四个 LIBERO 子基准上的细表。它显示小延迟时几乎不伤精度,同时已经开始带来1.17x到1.31x的时间收益;更大延迟时速度收益继续放大,但精度会开始小幅下降。
Results. As shown in Table 1, VLASH demonstrates strong performance across all LIBERO benchmarks under various inference delays. With small inference delays, VLASH maintains comparable accuracy to synchronous inference while achieving speedups of and , respectively. As the inference delay increases, the time advantages become more pronounced, achieving up to speedup at delay 3. Although accuracy decreases slightly at higher delays, VLASH still achieves strong performance across all tasks, demonstrating an effective accuracy-latency trade-off. We also evaluate on SmolVLA [31], with detailed results provided in supplementary materials.
💡 核心分析: VLASH 在轻到中等延迟下能保持接近同步的成功率,同时获得更好的时间表现;在更大延迟下虽然有轻微精度损失,但整体仍具实用价值。
5.2 Real-World Evaluation
To evaluate VLASH in real-world settings, we deploy [16] on two robotic platforms: the Galaxea R1 Lite [13] and the LeRobot SO-101 [15]. The R1 Lite is a dual-arm robot equipped with two 7-DOF arms from Galaxea [12]. The SO-101 is a 6-DOF collaborative robotic arm from LeRobot [5]. For , we apply a projection layer to map the robot state into an embedding, bypassing the tokenizer instead of incorporating it into the language prompt in the original implementation. We design our real-world experiments to evaluate three key aspects: (1) Accuracy: the success rate of completing manipulation tasks; (2) Efficiency: the task completion time and motion smoothness; and (3) Reaction speed: the latency to react to dynamic changes in the environment.
💡 动机批注: 真实世界部分把实验落在两个具体平台上,并明确分成 Accuracy、Efficiency、Reaction speed 三个评价维度。这里的关注点已经从“会不会失稳”变成“真实机器人是不是更流畅、更快、反应更及时”。
5.2.1 Accuracy and Efficiency
Experimental Setup. Following the setup in SmolVLA [31], we evaluate on three manipulation tasks that test different aspects of robotic control. We set the execution horizon to steps at . All experiments are conducted on a laptop with NVIDIA RTX 4090 GPU, with an inference delay of 4 steps. On our robotic platforms, we evaluate three tasks:
💡 实现细节: 这一段给出真实操控实验的基准设定:
π0.5模型,预测步长H=50,每次执行步数K=24,控制频率30Hz。基于 RTX 4090 测试,人为设定了 4 步的推理延迟。这套参数比仿真更贴近工业界双臂机器人的实际运行规格。
-
Pick and Place: pick up a cube from varying starting
positions and place it into a fixed box; -
Stacking: pick up a blue cube and stack it on top of
an orange cube, where both cubes’ initial positions vary across episodes; -
Sorting: sort cubes by color, placing the orange cube in the left box and the blue cube in the right box, with cube positions varying across episodes.
For each task, we conduct 16 rollouts per method and report both the score percentage and the task completion time. The score percentage is calculated based on a 2-point scoring system per rollout: 1 point for successfully picking up the object, and 1 point for completing the task. We compare synchronous inference, naive asynchronous inference, and VLASH across these tasks.
💡 技术细节: 三类任务分别对应基础抓放、需要精确相对位姿的堆叠,以及更接近组合任务的 sorting。这样设计能同时观察流畅性、精度和任务完成时间。
每个 task 每种方法做 16 次 rollout,并用 2-point scoring 统计“抓起”和“完成任务”两个层级的成功,这样既能看最终结果,也能看任务中途是否更容易掉链子。
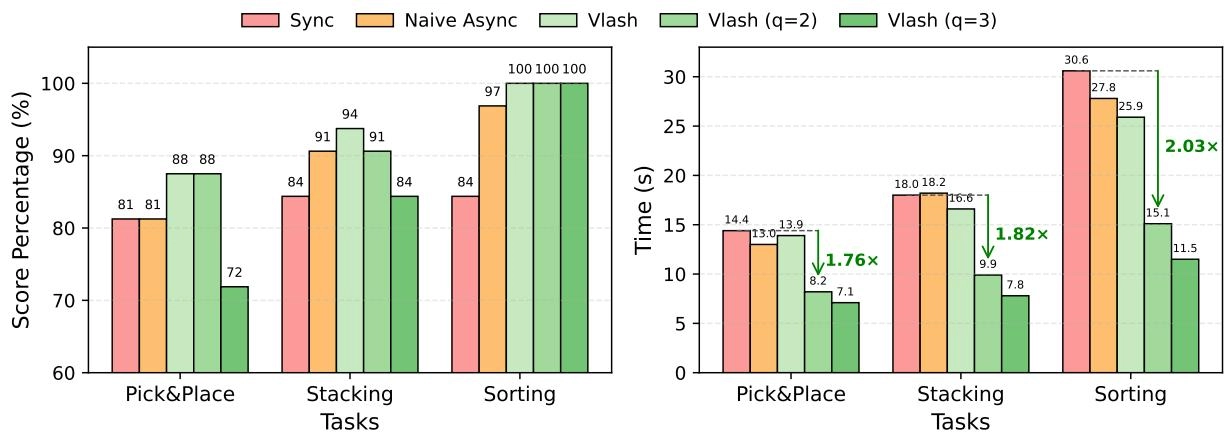
Figure 7. Real-world evaluation results on manipulation tasks. We evaluate [16] on three tasks with different inference methods. Left: Score percentages (based on 2-point scoring: 1 for success of picking up the object, 1 for task completion) of VLASH and baselines across three tasks. Right: Task completion times with green arrows indicating speedup of VLASH relative to synchronous baseline. VLASH applies action quantization with quantization ratio .
💡 实验结论: Figure 7 给出了真实机器人里最直观的结果:左图看分数,右图看任务时间。绿色箭头强调的是叠加 action quantization 后,VLASH 相对同步基线的速度收益。
Results. As shown in Fig. 7, VLASH delivers better or comparable score percentage to synchronous inference while significantly reducing task completion time across all tasks. Specifically, VLASH maintains an average score percentage, outperforming synchronous baseline and naive asynchronous inference , while completing tasks in 18.8 seconds on average compared to 21 seconds for synchronous inference, which is a speedup.
💡 核心分析: 不加激进量化时,VLASH 已经能在平均分数上超过同步与 naive async,同时把平均完成时间从 21 秒压到 18.8 秒。这说明 future-state-aware async 本身就能兼顾精度和效率。
Furthermore, by applying action quantization, we can achieve greater speedups with minimal accuracy loss. VLASH with achieves up to speedup, while maintaining the original accuracy. With a more aggressive quantization ratio of , VLASH achieves the faster execution at up to speedup, with only a modest drop in average score percentage, which demonstrates a favorable speed-accuracy trade-off.
💡 核心原理:
2.03x和2.67x则来自进一步叠加 action quantization。论文 headline 中最大的速度收益是 alignment 加上更粗粒度执行共同带来的。
5.2.2 Reaction Speed
Experimental Setup. To evaluate the reaction speed improvement of asynchronous inference, we compare the maximum reaction latency between synchronous and asynchronous inference across different hardware configurations. Following the setup in [16], we set the execution horizon to for synchronous inference and a control frequency of [4, 16], resulting in an execution duration of approximately 0.5 seconds per action chunk. We measure the model inference latency of on three different GPUs: RTX 5090, RTX 4090, and RTX 5070, using torch.compile to enable CUDAGraph optimization and kernel fusion for minimal latency [2].
💡 实验设计: reaction speed 实验量测的是最大反应延迟,而不是任务总时间。设置
K=25、50Hz 后,同步推理的反应延迟本质上等于“整段 chunk 执行时间 + 推理时间”,async 则主要看推理时间本身。

Table 2. Reaction speed comparison across devices. Latency of [16] with 1 image input, at . Execution duration is . Max reaction latency execution duration inference latency for Sync, inference latency only for Async.
💡 实验结论: Table 2 把这个差异定量化了。在 RTX 5090 上,sync 约 530.4ms,而 async 只有 30.4ms,因此得到
17.4x的 reaction-latency speedup
Results. As shown in Table 2, asynchronous inference significantly reduces the maximum reaction latency compared to synchronous inference, achieving up to speedup. To showcase the fast reaction and smooth control capabilities of VLASH, we train to perform highly dynamic interactive tasks: playing ping-pong with a human and playing whack-a-mole. These tasks demand both rapid reaction to dynamic changes and smooth continuous motion to maintain control accuracy. To the best of our knowledge, we are the first to demonstrate a VLA successfully playing ping-pong rallies with a human. Under synchronous inference, the robot’s reaction is too slow to track the fast-moving ball, while VLASH enables real-time response and stable rallies. We encourage readers to view the demo videos in the supplementary materials to see the dynamic performance of VLASH in action.
💡 核心洞察: 这一段顺便把 ping-pong 和 whack-a-mole 作为高动态 showcase。由于这两种游戏对微小延迟极其敏感,一旦卡顿就会全盘皆输,所以它们是检验“实时反应速度”和“平滑度”的试金石。VLASH 不只是跑分好,它在实际上让大参数 VLA 在真机上打乒乓球成为了可能。
5.3 Fine-tuning Efficiency
Experimental Setup. We evaluate the training efficiency gains from our efficient fine-tuning with shared observation approach. A key consideration is that training with multiple temporal offsets using shared observation effectively increases the effective batch size by a factor equal to the number of offsets. Therefore, we compare our method against standard fine-tuning under the same effective batch size to ensure a fair comparison. Specifically, we conduct experiments on the LIBERO benchmark using [16] trained on GPUs with DDP [21]. For our method, we use with a physical batch size of 4 per GPU, resulting in an effective batch size of 16 per GPU and 64 in global. The standard baseline uses a physical batch size of 16 per GPU to match this effective batch size. Both methods are trained for 10K, 20K, and 30K iterations, and we report the average success rate across all LIBERO tasks. We also measure the training time per forward-backward pass to quantify the speedup.
💡 实验设计: 训练效率实验最重要的控制变量是“相同 effective batch size”。只有这样,shared-observation 带来的加速才不是因为偷偷增加了总样本量。

Table 3. Fine-tuning efficiency. Original (without offset augmentation) vs VLASH (with offset augmentation and shared observation) on LIBERO with [16]. Training on GPUs using DDP, with effective batch size 16 per GPU (total 64). We report average LIBERO scores at different training steps. Both evaluated under synchronous inference.
💡 微调数据:
- Original:没有 offset augmentation
- VLASH:offset augmentation + shared observation
另外控制两边 effective batch size 一样
Results. As shown in Table 3, VLASH converges more slowly in the early stages but ultimately achieves comparable accuracy to standard fine-tuning. Although more training steps are needed for convergence, each step is significantly faster, achieving a speedup per step. This efficiency gain comes from encoding the shared observation only once and reusing it across all temporal offsets. Furthermore, since both methods are evaluated under synchronous inference, these results also demonstrate that VLASH does not hurt the original synchronous performance of the model.
💡 核心分析: 最终结论也比较务实:VLASH 早期收敛稍慢,但终点精度与标准 fine-tuning 接近;既然同步评测下也没有明显伤害原模型性能,说明这套训练 recipe 至少是站得住的。
🔖 Section 总结
核心洞察
- Kinetix 证明 VLASH 在高动态、大 delay 条件下比 naive async 和 RTC 更稳。
- LIBERO 说明它对相对静态任务也能保持较好的 accuracy-latency trade-off。
- 真实世界里的最大速度 headline 需要拆开看:future-state alignment 与 action quantization 都有贡献。
- shared-observation 不是附带优化,而是让整套训练方法真正可用的关键。
- 对实时控制的意义: 大量且全面的实验证实,这不只是跑出好分数的 Trick,而是真正可以在真机上应用、且不会显著拉垮已有表现的泛化技术。
6 Conclusion
📌 预览
Conclusion 回收全文主线:VLASH 通过 future-state-aware asynchronous inference 弥合 prediction-execution gap,在仿真和真实机器人上同时给出更流畅、更准确、也更快的控制。随后作者用一小段致谢说明这项工作背后的计算与资助背景。
We present VLASH, a general and efficient framework for enabling asynchronous inference in Vision-Language-Action models. By making the policy future-state-aware through simple state rollforward, VLASH effectively bridges the prediction-execution gap that has hindered asynchronous control. Experiments on both simulated and real-world benchmarks demonstrate that VLASH achieves smooth, accurate, and fast-reaction control, consistently matching or surpassing the accuracy of synchronous inference while providing substantial speedups. Moreover, we demonstrate that VLAs can perform highly dynamic tasks such as playing ping-pong rallies with humans. We hope these results will inspire future research toward extending VLAs to more dynamic and physically interactive domains.
💡 核心分析: 结论段的重点是把 VLASH 重新定义为一个“通用且高效的 async inference framework”,而不只是某个特定模型的小技巧。作者也再次强调 ping-pong 这种高动态任务,说明他们最看重的是实时互动能力。
通过简单的状态前滚使策略具有“未来状态感知”的能力,VLASH 有效地弥合了长期阻碍异步控制的预测-执行差距。
We thank MIT-IBM Watson AI Lab, Amazon and National Science Foundation for supporting this research. We thank NVIDIA for donating the DGX server.
🔖 Section 总结
核心洞察
- VLASH 的主张是:只要把 state 对齐到执行时刻,异步推理就能既快又稳。
- 作者希望把 VLA 从缓慢、间断的演示推进到更动态的真实交互。
- 从结论措辞看,future-state awareness 被视为一种通用框架,而不是某个模型专属 hack。
- 对实时控制的意义: 该工作提供了一条从根本上解决系统延迟问题的极简路径——通过预测物理世界来对齐控制指令,为下一代高响应性机器人的部署提供了可靠基础。
7 Appendix
📌 预览
附录补了三类正文外的重要信息:SmolVLA 上的泛化结果、完整训练超参数,以及补充视频与 π0.5 的 state 输入改造说明。它们分别对应“方法能否迁移”“实验是否可复现”“为什么某些架构更需要 state projection”这三件事。
7.1 SmolVLA Results on LIBERO Benchmarks
To further evaluate the generalization of VLASH across different VLAs, we conduct additional experiments on SmolVLA-450M [31], a compact yet efficient vision-language-action model. Following the same experimental setup as described in Sec. 5.1.2, we fine-tune SmolVLA on the LIBERO benchmark [23] for 30K iterations with a batch size of 32. We evaluate the model across four LIBERO subbenchmarks (Spatial, Object, Goal, and LIBERO-10) under various inference delays ranging from 0 to 4 steps, with an execution horizon of .
💡 泛化实验: 这一节的作用是把 VLASH 从
π0.5扩展到另一类更紧凑的 VLA。若这里也成立,说明方法并不依赖某一个特定 backbone。

Table 4. Performance on LIBERO benchmarks with SmolVLA-450M and different inference delays. We evaluate SmolVLA across four LIBERO sub-benchmarks (Spatial, Object, Goal, LIBERO-10) under various inference delays (1 to 4 steps). SR: average success rate; Steps: average execution steps to task completion; Latency: inference latency in seconds.
As shown in Table 4, VLASH achieves consistent speedups across all inference delays when applied to SmolVLA. At delay 2 and 3, VLASH achieves up to speedup compared to synchronous inference. While the success rate shows minor variations across different delays, VLASH at delay 3 achieves success rate, which is comparable to the synchronous baseline , demonstrating that VLASH can maintain performance while providing significant latency improvements. These results further validate that VLASH generalizes effectively across different VLA architectures.
💡 实验结论: Table 4 显示在 SmolVLA-450M 上,VLASH 仍然能持续带来
1.17x到1.35x的速度收益,而且在 delay=3 时成功率79.06%与同步基线78.96%基本持平。作者据此把 VLASH 描述为对不同 VLA architecture 都有效的 async 框架。
7.2 Experimental Details
We present the detailed training hyperparameters used for fine-tuning VLAs in our experiments in Table 5. For all experiments on LIBERO benchmarks and real-world tasks, we use the same hyperparameters to ensure fair comparison across different methods and models. These hyperparameters are carefully tuned to balance training stability and convergence speed while preventing overfitting on the downstream tasks.
💡 技术细节: 这段主要服务复现。它说明正文所有 LIBERO 和 real-world fine-tuning 实验都共用一套超参数,避免不同方法因为 recipe 差异而失去可比性。

Table 5. Training hyperparameters for fine-tuning VLAs. We use these hyperparameters for fine-tuning and SmolVLA on LIBERO and real-world tasks.
💡 Table 5 批读: 常规 fine-tuning 组合
7.3 Supplementary Demo Video
We provide comprehensive video demonstrations comparing our method against synchronous and naive asynchronous baselines across various real-world manipulation tasks. All demonstrations are conducted using [16] deployed on a laptop with NVIDIA RTX 5090 GPU, achieving an inference frequency of .
We showcase the following tasks in the supplementary materials:
- Ping-pong: Interactive rallies with a human player, demonstrating rapid reaction capabilities.
- Whack-a-mole: Fast-response game requiring quick detection and precise striking motions.
- Pick and place: Standard manipulation task showing smooth motion control.
- Folding clothes: Complex manipulation requiring coordinated movements.
We compare three inference modes: synchronous inference, naive asynchronous inference, and VLASH. Additionally, we demonstrate the effects of action quantization, showing how our method can achieve further speedups while maintaining task performance.
💡 实验设计: 补充视频使用 RTX 5090、15Hz 推理频率,目标是直观看到同步、naive async 和 VLASH 在真实机器人上的动作差异,覆盖了高动态交互任务与常规操控任务,因此不仅能看反应速度,也能看轨迹连续性和执行平滑度。作者还在视频里专门比较了 action quantization,这有助于把“方法本身更稳”和“执行更粗因此更快”两种收益分开观察。
The video demonstrations clearly show that VLASH produces noticeably smoother motions and faster task completion compared to both synchronous and naive asynchronous baselines. The synchronous baseline often exhibits stuttering behavior due to action stalls, while naive asynchronous inference suffers from prediction-execution misalignment that leads to erratic movements. In contrast, VLASH maintains fluid motion throughout task execution while achieving significant speedup. We encourage readers to view the video to appreciate the dynamic performance improvements of our approach.
💡 核心分析: smoothness、stuttering、erratic movement 这类现象很难只靠表格完全传达。
7.4 Architectural Modifications
A key advantage of VLASH is that it requires no architectural modifications to achieve effective performance across diverse VLA models. Since all current VLA models accept robot state inputs, VLASH can be applied directly by simply offsetting the state information during fine-tuning to account for inference delay. This straightforward approach enables the model to learn the temporal alignment between delayed observations and corresponding actions without any changes to the model architecture.
For standard VLA architectures like [3] and SmolVLA [31], which incorporate a state projection layer to embed proprioceptive state vectors into continuous representations before feeding them into the transformer backbone, VLASH integrates seamlessly and achieves excellent results out of the box.
💡 批读: VLASH 的默认立场是不需要改架构,只需在 fine-tuning 时对 state 做 offset。也就是说,方法设计目标首先是最小侵入,对于像
π0或 SmolVLA 这种本来就有 state projection layer 的模型,VLASH 能直接复用现有 proprioceptive state 通路,因此迁移起来更顺手。
We further note that VLASH also works directly with [16] without modifications, as demonstrated in our experiments in Table 1. However, employs a unique design that converts numerical state values into text tokens and appends them to the language prompt. This text-based encoding forces numerical state values through tokenization and one-hot encoding, disrupting their inherent numerical structure and making it more challenging for the model to learn from state information. For such architectures, we find that adding a lightweight state projection like the design of and injecting the resulting embeddings back into their original positions can further enhance smoothness and stability. A simpler alternative is to incorporate the projected state embeddings into the AdaRMSNorm layers as conditioning signals alongside timestep embeddings. While entirely optional (and VLASH already performs well without it), this small architectural enhancement consistently improves control smoothness for . Importantly, the additional parameters introduced by this state projection layer are negligible: it consists only of a linear mapping from the state dimension to the hidden dimension. Moreover, because it is zero-initialized, it completely preserves the pretrained model’s performance during the initial stages of fine-tuning.
💡 技术细节:
π0.5的 state 是经由文本 token 注入的,这会破坏数值结构,所以作者额外指出轻量 state projection 可能进一步改善平滑度与稳定性。这个讨论很关键,因为它说明 VLASH 的效果一部分取决于 state 入口本身是否合适。
🔖 Section 总结
核心洞察
- SmolVLA 结果表明 VLASH 不是单模型特例。
- Table 5 说明这套方法的训练 recipe 并不离谱,具备复现可行性。
- 对
π0.5来说,state 该如何进入模型本身就是性能上限的一部分。 - 对实时控制的意义: 架构的微小调优(如补充 state projection)在异步部署中能显著影响最终的运动平滑度,提醒工程师在落地时不能完全忽视模型底层的数据流向。