Quantization模型量化
Transformer量化的核心挑战:激活离群值与分布特性
与卷积神经网络(CNN)相比,Transformer模型的量化难度显著更高。这一差异的根源在于Transformer内部独特的激活分布特性,尤其是随着模型规模扩大而涌现的“系统性离群值”。
已有研究表明,当Transformer模型参数量超过67亿(6.7B)时,激活矩阵中会涌现出极端的离群值。这些离群值并非随机噪声,而是具有高度的结构化特征:它们通常集中在特定的通道(Channel)或特征维度上,且幅度可达中位数的100倍以上。这种现象在残差连接(Residual Connections)和层归一化(LayerNorm)之后尤为明显。
从机制上看,这些离群值在注意力机制中扮演着关键角色,往往对应着特定的功能性Token(如分隔符或高频特征),是模型捕捉长距离依赖和特定语义的关键。然而,这种极端的动态范围对量化器构成了灾难性挑战。传统的Min-Max均匀量化会将量化网格(Grid)拉伸以覆盖最大值,导致绝大多数分布在零点附近的“正常”数值被压缩到极少数的量化区间内,甚至直接被归零,。这种精度的丧失会直接导致模型困惑度(Perplexity)飙升,推理能力崩塌。
后训练量化(PTQ)
后训练量化(Post-Training Quantization, PTQ)因其无需重新训练、仅需少量校准数据(Calibration Data)的特性,成为了大模型部署的首选方案。近年来,PTQ技术经历了从简单的舍入策略到基于优化的复杂算法的演变。
GPTQ(Generative Pre-trained Transformer Quantization)
Accurate Post-Training Quantisation for Generative Pre-Trained Transformers
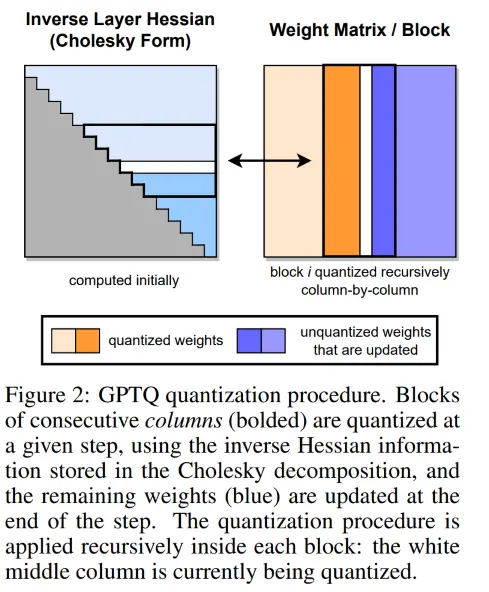
基于Optimal Brain Quantization(OBQ)理论,利用二阶信息(海森矩阵H的逆)来迭代地更新未量化的权重,以补偿量化当前权重所引入的误差。GPTQ能够将模型量化至3-bit或4-bit而保持极高的精度,但其算法依赖于权重的分组重排(Group Reordering),这在实际推理中可能导致不规则的内存访问,增加了工程实现的复杂度。
AWQ(Activation-aware Weight Quantization)
Activation-aware Weight Quantization For On-Device LLM Compression And Acceleration
- 论文链接:https://arxiv.org/pdf/2306.00978
- 仓库地址:https://github.com/mit-han-lab/llm-awq?tab=readme-ov-file

AWQ(Activation-aware Weight Quantization)基于一个关键观察:并非所有权重都同等重要。权重的显著性(Salience)不应仅由其自身的幅度决定,而应结合其对应激活值的幅度来判断。AWQ通过观察少量校准数据中的激活分布,识别出那1%的显著权重,并在量化前对其进行放大(同时缩小对应的激活通道),从而在不改变计算结果的前提下保护了关键信息。AWQ的优势在于其不依赖梯度的反向传播或二阶矩阵计算,且不需要对权重进行重排,这使得其推理内核(Kernel)更容易优化,尤其是在vLLM等推理框架中,AWQ往往表现出比GPTQ更好的吞吐量稳定性。
QuaRot
Outlier-Free 4-Bit Inference in Rotated LLMs
QuIP#
Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
SpinQuant
LLM Quantization with Learned Rotations
量化感知训练(QAT)
量化感知训练(QAT)通过在训练过程中模拟量化噪声,使模型学会“适应”低精度表示
QLoRA
Efficient Finetuning of Quantized LLMs
BitNet
BitNet Distillation